
Last update : April 22, 2015
Festival
The Festival Speech Synthesis System is a general multi-lingual speech synthesis system originally developed by Alan W. Black at the Centre for Speech Technology Research (CSTR) at the University of Edinburgh. Alan W. Black is now professor in the Language Technology Institute at Carnegie Mellon University where substantial contributions have been provided to Festival. The program is written in C++.
To set-up a complete Festival Environment on OS X (Yosemite 10.10.2), four packages are required :
- Festival-2.4 (file festival-2.4-release.tar)
- Edinburgh Speech-Tools (file speech_tools-2.4-release.tar)
- Festvox (file festvox-2.7.0-release.tar.gz)
- Languages (example file : english festvox_kallpc16k.tar.gz)
To compile and install the packages, I got some guidance from a Linguistic Mystic (alias Will Styler). After unzipping, the files have been moved into a common folder Festival-TTS on the desktop with the following names :
- festival
- speech-tools
- festvox
The language files are installed in the festival folder in the sub-folders lib/voices/english.
The packages have been compiled in the following sequence :
mbarnig$ cd Desktop/Festival-TTS/speech_tools
mbarnig$ ./configure
mbarnig$ make
mbarnig$ make test
mbarnig$ make installmbarnig$ cd Desktop/Festival-TTS/festival
mbarnig$ ./configure
mbarnig$ make
mbarnig$ make installmbarnig$ cd Desktop/Festival-TTS/festvox
mbarnig$ ./configure
mbarnig$ makeAt the end the voice folder with the language files was moved to the festival/lib directory.
After updating Xcode to version 6.1.1 and installing the audiotools for Xcode 6.1, I checked that afplay is working :
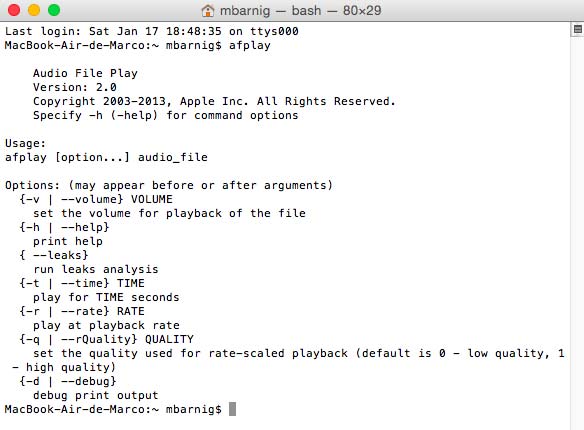
afplay check
I checked also that the festival/lib/siteinit.scm file contains the following statements :
- (Parameter.set ‘Audio_Required_Format ‘riff)
- (Parameter.set ‘Audio_Method ‘Audio_Command)
- (Parameter.set ‘Audio_Command “afplay $FILE”)
The following files have been downloaded from the festvox website, unzipped and moved to the festival/lib/dicts folder :
- festlex_CMU.tar.gz
- festlex_OALD.tar.gz
- festlex_POSLEX.tar.gz
I added finally the following statements to the .bash_profile file located in the homefolder (/Users/mbarnig) :
- export FESTIVALDIR=”/Users/mbarnig/Desktop/Festival-TTS/festival”
- export PATH=”$FESTIVALDIR/bin:$PATH”
- export ESTDIR=”/Users/mbarnig/Desktop/Festival-TTS/speech_tools”
- export PATH=”$ESTDIR/bin:$PATH”
- export FESTVOXDIR=”/Users/mbarnig/Desktop/Festival-TTS/festvox”
The festival tool can now be started in the terminal window with the command
mbarnig$ $FESTIVALDIR/bin/festival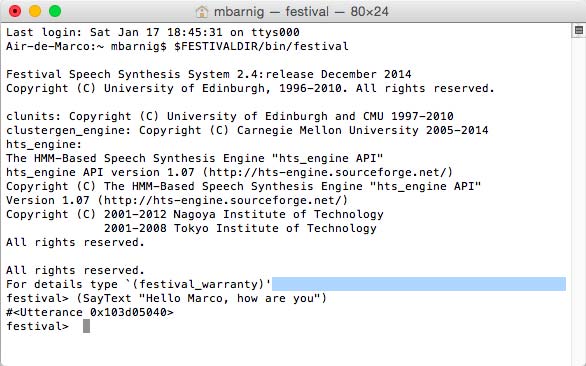
Festival version 2.4
All seems to be working great!
Festival embeds a basic small Scheme (Lisp) interpreter (SIOD : Scheme In One Defun 3.0) written by George Carrett.
Festival works in two fundamental modes, command mode and text-to-speech (tts) mode. If Festival is started without arguments (or with the option –command), it enters the default command mode (prompt = festival>). Information included in paranthesis is treated as commands and is interpreted by the Scheme interpreter. The following commands are accepted:
festival>
> (intro) : short spoken introduction
> (voice.list) : list of available voices
> (set! utt1 (Utterance Text "Hello world")) :
create an utterance and save it in a variable
> (utt.synth utt1) : synthesize utterance to get a waveform
> (utt.play utt1) : send the synthesized waveform to the audio device
> (SayText "Good morning, welcome to Festival") :
speak text (combination of the 3 preceding commands)
> (tts "myfile" nil) : speak file instead of text
> (manual nil) : show the content of the manual
> (manual "Accessing an utterance") : show the section "utterance"
> (PhoneSet.list) : show the currently defined phonesets
> (tts "doremi.xml" 'singing) : an XML based mode for specifying
songs, both notes and duration
> (quit) : exitIf Festival is started with the –tts option, it enters tts-mode. Information (in files or through standard input) is treated as text to be rendered as speech.
Other options available at the start of Festival are :
--language LANG : set the default language to LANG.
--server : enter server mode where Festival waits for clients on a
known port (default port : 1314); connected clients may send
commands (or text) to the server and expect waveforms back.
--script scriptfile : run scriptfile as a Festival script file.
--heap NUMBER : to increase the scheme heap.
--batch : after processing file arguments do not become interactive.
--interactive : after processing file arguments become interactive.Script mode :
festival mbarnig$ examples/saytime
festival mbarnig$ text2wave myfile.txt -o myfile.wavAn updated Festival System Documentation with 34 chapters, edited in December 2014, is available at the festvox website.
The following Festival voices are available :
- festvox_cmu_us_ahw_cg
- festvox_cmu_us_aup_cg
- festvox_cmu_us_awb_cg
- festvox_cmu_us_axb_cg
- festvox_cmu_us_bdl_cg
- festvox_cmu_us_clb_cg
- festvox_cmu_us_fem_cg
- festvox_cmu_us_gka_cg
- festvox_cmu_us_jmk_cg
- festvox_cmu_us_ksp_cg
- festvox_cmu_us_rms_cg
- festvox_cmu_us_rxr_cg
- festvox_cmu_us_slt_cg
- festvox_kallpc16k
- festvox_rablpc16k
- Leopold : AustrianGerman
- IMS German Festival
- OGIgerman by CSLU
- Swedish by SOL
- Hindi
Hindi and German are examples of Festival languages/voices with different phone-features in the phone-set as in the standard us and english phone-sets.
Edinburgh Speech Tools
The Edinburgh Speech Tools Library is a collection of C++ class, functions and related programs for manipulating objects used in speech processing. It includes support for reading and writing waveforms, parameter files (LPC, Ceptra, F0) in various formats and converting between them. It also includes support for linguistic type objects and support for various label files and ngrams (with smoothing). In addition to the library a number of programs are included. An intonation library which includes a pitch tracker, smoother and labelling system (using the Tilt Labelling system), a classification and regression tree (CART) building program called wagon. Also there is growing support for various speech recognition classes such as decoders and HMMs.
An introduction to the Edinburgh Speech Tools is provided by Festvox.
Festvox
The Festvox project aims to make the building of new synthetic voices for Festival more systemic and better documented, by offering the following resources :
- Documentation
- Aids to building synthetic voices for limited domains
- Specific scripts to build new voices
- Example Speech Databases
- Demos
- Discussion list
Festival Variables
Festival provides a list of variables available for general use. This list is automatically generated from the documentation strings of the variables defined in the source code. A variable can be displayed with the print command at the festival prompt. Some examples are shown hereafter :
festival>
> (print festival_version) ; current version of the system
> (print *ostype*) ; operation system that Festival is running on
> (print lexdir) ; default directory of the lexicons
> (print SynthTypes) ; list of synthesis types and functions
> (print token.letter_pos) ; POS tag for individual letters
> (print token.punctuation) ; characters treated as punctuation
> (print voice-path) ; list of folders to look for voices
> (print voice_default) ; function to load the default voice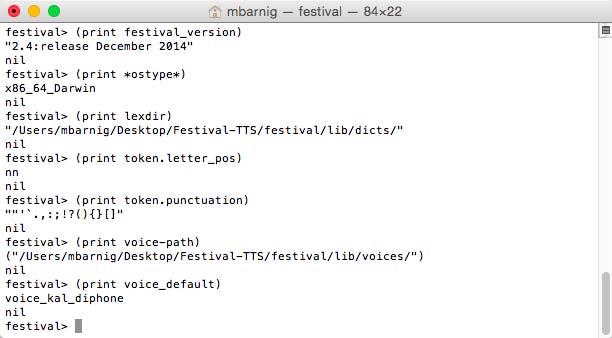
Festival Variables
Festival Functions
Festival provides a list of functions available for general use. This list is automatically generated from the documentation strings of the functions defined in the source code. A function is called at the Festival prompt. Some examples are shown hereafter :
festival>
> (pwd) ; return current directory
> (lex.list) ; list names of all currently defined lexicons
> (voice.list) ; list all potential voices in the system
> (lex.lookup WORD FEATURES) ; lookup word in current lexicon
> (lex.compile ENTRYFILE COMPILEFILE) ; compile lexical entries
> (PhoneSet.list) ; list all currently defined PhoneSets
> (quit) ; exit from Festival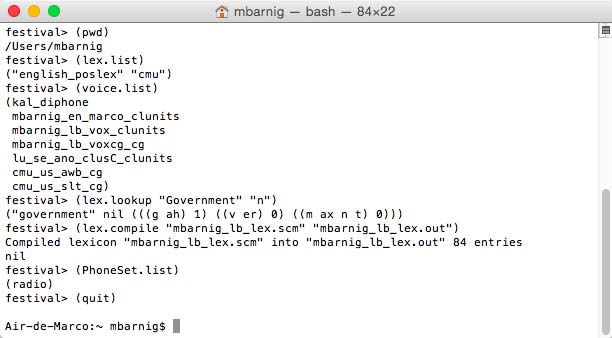
Festival Functions
Utterance Access Methods
Festival provides a number of standard functions that allow to access parts of an utterance, to traverse through it and to extract features.
Three utterances access methods are of particular interest :
- (utt.feat UTT FEATNAME)
returns the value of feature FEATNAME in UTT - (item.feat ITEM FEATNAME)
returns the value of feature FEATNAME in ITEM - (utt.features UTT RELATIONNAME FUNCLIST)
returns vectors of feature values for each item, listed in FUNCLIST and related
in RELATIONNAME in UTT
FEATNAME may be a
- feature name ; example : (item.feat sylb ‘stress)
- feature function name ; example : (item.feat sylb ‘pos_in_word)
- pathname ; examples : (item.feat sylb ‘nn.stress)
(item.feat sylb ‘R:SylStructure.parent.word)
Notes :
sylb is a syllable item
R: is a relation operator
RELATIONNAME may be ‘Token, ‘Word, ‘Phrase, ‘Segment, ‘Syllable, etc
FUNCLIST is a list of items ; example : ‘(name pos)
Some examples are shown hereafter :
festival>
(set! utter (SayText "Hello Marco, how are you?"))
(set! tok (utt.relation.first utter 'Token))
(utt.feat utter 'type)
(item.feat tok 'nn.name)
(item.feat tok 'R:Token.daughter1.name)
(utt.features utter 'Word '(name pos p.pos n.pos))
Utterance access methods
More informations about feature functions as FEATNAME are provided in the next chapter.
Festival Feature Functions
Festival provides a list of basic feature functions available as FEATNAME in utterances. Most are only available for specific items. Some examples are shown hereafter, related to the corresponding items :
Token item
festival>
(set! utter (SayText "Hello Marco, how are you?"))
(set! tok (utt.relation.first utter 'Token))
(item.name tok) ; first token
(item.feat tok 'name) ; first token
(item.feat tok 'n.name) ; second token
(item.feat tok 'nn.name) ; third token
(item.feat tok 'whitespace)
(item.feat tok 'prepunctuation)
Utterance Token
Word item
festival>
(set! utter (SayText "Hello Marco, how are you?"))
(set! wrd (item.next (utt.relation.first utter 'Word)))
(item.name wrd) ; second word
(item.feat wrd 'p.name) ; first word
(item.feat wrd 'cap)
(item.feat wrd 'word_duration)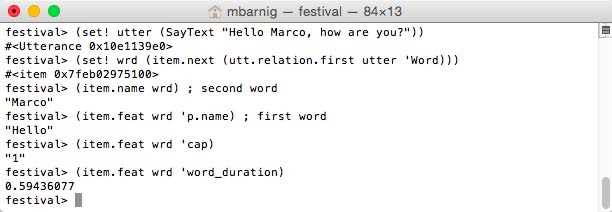
Utterance Word
Segment item
festival>
(set! utter (SayText "Hello Marco, how are you?"))
(set! seg (item.prev (item.prev (utt.relation.last utter 'Segment))))
(item.name seg) ; third last segment
(item.feat seg 'n.name) ; second last segment
(item.feat seg 'seg_pitch)
(item.feat seg 'segment_end)
(item.feat seg 'R:SylStructure.parent.parent.name)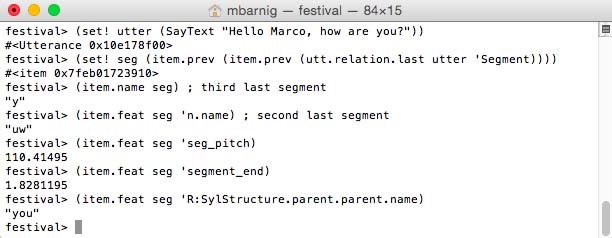
Utterance Segment
Syllable item
festival>
(set! utter (SayText "Hello Marco, how are you?"))
(set! sylb (utt.relation.first utter 'Syllable))
(item.features sylb) ; first syllable
(item.feat sylb 'asyl_out)
(item.feat sylb 'syl_midpitch)
(utt.features utter 'Syllable '(stress))
(item.feat sylb 'nn.stress) ; stress of third syllable
(item.feat sylb 'R:SylStructure.parent.name)
(item.feat sylb 'R:SylStructure.daughter1.name)
(item.feat sylb 'R:SylStructure.daughter2.name)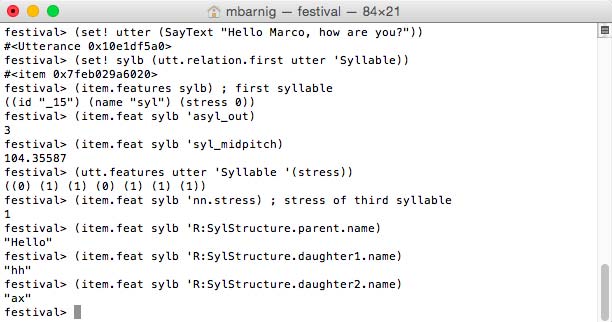
Utterance Syllable
SylStructure item
festival>
(set! utter (SayText "Hello Marco, how are you?"))
(set! sylst (item.prev (utt.relation.last utter 'SylStructure)))
(item.features sylst)
(item.feat sylst 'pos_index)
(item.feat sylst 'phrase_score)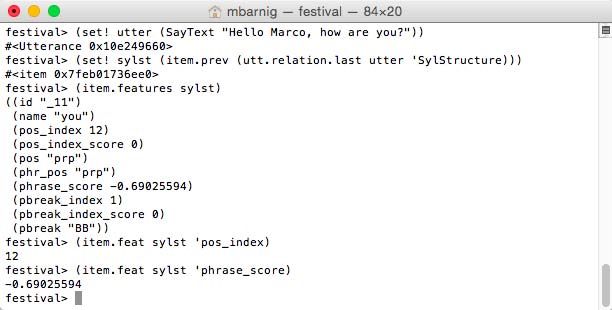
Utterance SylStructure
Intonation item
festival>
(set! utter (SayText "Hello Marco, how are you?"))
(set! inton (utt.relation.first utter 'Intonation))
(item.features inton)
(item.feat inton 'id)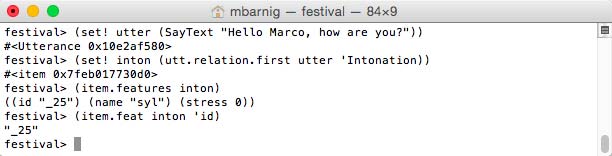
Utterance Intonation
Dumping features
Extracting basic features from a set of utterances is useful for most of the training techniques for TTS voice building. Festival provides a script dumpfeats in the festival/examples folder which does this task. The results can be saved in a single feature file or in separate files for each utterance. An example is shown below, the dumpfeats script was copied in the festival folder of my test voice mbarnig_lb_voxcg :
mbarnig$ ./dumpfeats -feats "(name p.name n.name)"
-relation Segment -output myfeats.txt utts/*.utt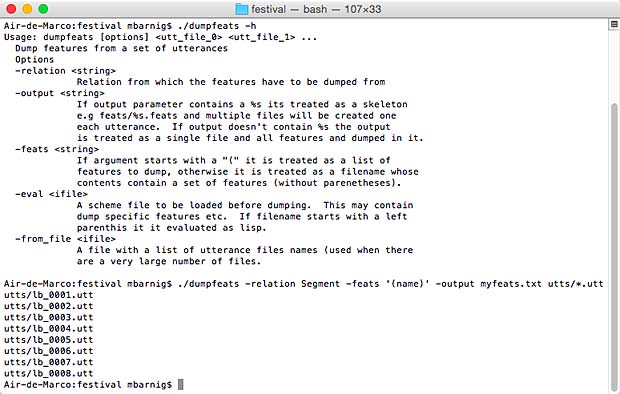
Festival dumpfeats
Links
A list of links to websites with additional informations about the Festival package is shown hereafter :
- Flinger – Festival Singer
- Festival output with regard to a singing voice
- Festival inofficial documentation (experimental doxygen-generated source code documentation), by Fossies