Introduction
Le titre de ma présente publication est le résultat d’une traduction automatique française -> allemande du début de la phrase “La bise et le soleil se disputaient, chacun assurant qu’il était le plus fort, quand ils ont vu un voyageur qui s’avançait, enveloppé dans son manteau”.
C’est le début d’une fable d’Ésope, extraite d’un ensemble de fables en prose qu’on attribue à l’écrivain grec Ésope. Le texte de la fable La bise et le soleil est utilisé régulièrement par des linguistes dans le cadre de projets de recherche sur le traitement du language naturel (NLP: Natural Language Processing). Cette fable a été traduite dans des centaines de langues mondiales et régionales. Comme je vais me référer plusieurs fois sur cette fable, je vais d’emblée présenter l’intégralité du texte dans les versions française, allemande, anglaise et luxembourgeoise ci-après.
Fables d’Ésope
Ls fables d’Ésope sont des centaines de textes et toutes sortes de récits qui circulaient oralement dans la Grèce antique et qui ont inspiré de nombreux auteurs comme Phèdre, Marie de France, Jean de la Fontaine. La fable d’Ésope La bise et le soleil est très courte, sa morale réside dans l’enseignement que la persuasion, plus lente, s’avère toutefois plus efficace que la violence.

La bise et le soleil
La bise et le soleil se disputaient, chacun assurant qu’il était le plus fort, quand ils ont vu un voyageur qui s’avançait, enveloppé dans son manteau. Ils sont tombés d’accord que celui qui arriverait le premier à faire ôter son manteau au voyageur serait regardé comme le plus fort. Alors, la bise s’est mise à souffler de toute sa force mais plus elle soufflait, plus le voyageur serrait son manteau autour de lui et à la fin, la bise a renoncé à le lui faire ôter. Alors le soleil a commencé à briller et au bout d’un moment, le voyageur, réchauffé, a ôté son manteau. Ainsi, la bise a dû reconnaître que le soleil était le plus fort des deux.
Norwind und Sonne
Einst stritten sich Nordwind und Sonne, wer von ihnen beiden wohl der Stärkere wäre, als ein Wanderer, der in einen warmen Mantel gehüllt war, des Weges daherkam. Sie wurden einig, daß derjenige für den Stärkeren gelten sollte, der den Wanderer zwingen würde, seinen Mantel abzunehmen. Der Nordwind blies mit aller Macht, aber je mehr er blies, desto fester hüllte sich der Wanderer in seinen Mantel ein. Endlich gab der Nordwind den Kampf auf. Nun erwärmte die Sonne die Luft mit ihren freundlichen Strahlen, und schon nach wenigen Augenblicken zog der Wanderer seinen Mantel aus. Da mußte der Nordwind zugeben, daß die Sonne von ihnen beiden der Stärkere war.
The northwind and the sun
The North Wind and the Sun were disputing which was the stronger, when a traveler came along wrapped in a warm cloak. They agreed that the one who first succeeded in making the traveler take his cloak off should be considered stronger than the other. Then the North Wind blew as hard as he could, but the more he blew the more closely did the traveler fold his cloak around him; and at last the North Wind gave up the attempt. Then the Sun shined out warmly, and immediately the traveler took off his cloak. And so the North Wind was obliged to confess that the Sun was the stronger of the two.
De Nordwand an d’Sonn
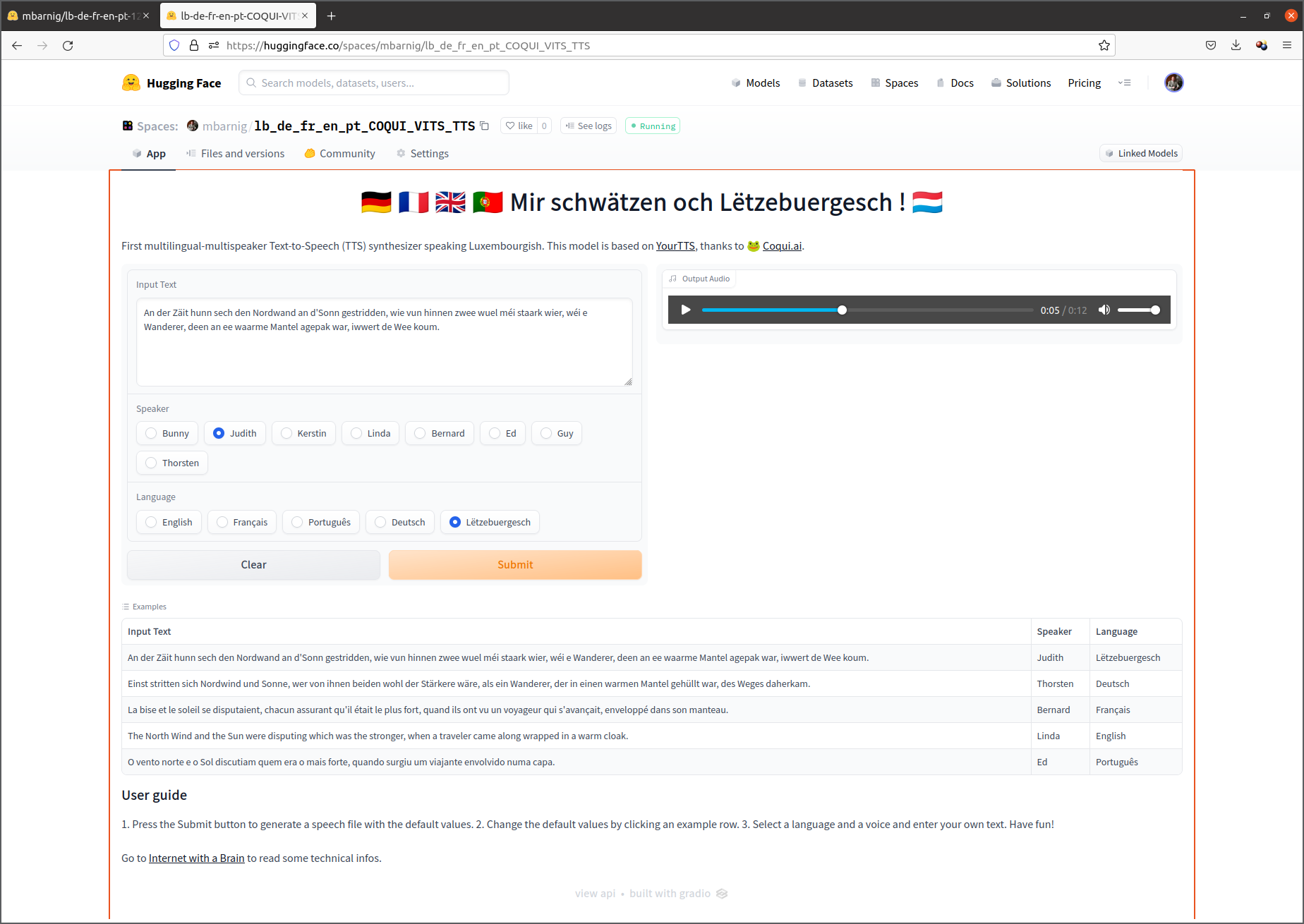
An der Zäit hunn sech den Nordwand an d’Sonn gestridden, wie vun hinnen zwee wuel méi staark wier, wéi e Wanderer, deen an ee waarme Mantel agepak war, iwwert de Wee koum. Si goufen sech eens, datt deejéinege fir dee Stäerkste gëlle sollt, deen de Wanderer forcéiere géif, säi Mantel auszedoen. Den Nordwand huet mat aller Force geblosen, awer wat e méi geblosen huet, wat de Wanderer sech méi a säi Mantel agewéckelt huet. Um Enn huet den Nordwand säi Kampf opginn. Dunn huet d’Sonn d’Loft mat hire frëndleche Strale gewiermt, a schonn no kuerzer Zäit huet de Wanderer säi Mantel ausgedoen. Do huet den Nordwand missen zouginn, datt d’Sonn vun hinnen zwee dee Stäerkste wier.
Histoire de la traduction automatique au Luxembourg et au delà
Le Luxembourg figure parmi les pionniers dans l’utilisation de la traduction automatique du fait que les nombreuses institutions européennes, ayant leur siège dans le pays, doivent gérer leurs documents dans les différentes langues officielles de la communauté européenne. Hélas, le luxembourgeois ne fait pas partie de ces languages et ce n’est que récemment que la langue luxembourgeoise est supporté par les systèmes de traduction automatique.
Tout a commencé au début des années 1950 avec la fondation de la Communauté européenne du charbon et de l’acier (CECA) par six nations européennes, dont le Luxembourg. La CECA a été dirigée par la Haute Autorité qui siégeait à Luxembourg et qui gérait quatre langues officielles: français, allemand, italien et néerlandais.

A la même époque, Warren Weaver, un mathématicien américain, concrétisait ses idées au sujet de la traduction automatique, communiquées en mars 1947 au cybernéticien Norrbert Wiener et publiées en juillet 1949 dans un mémorandum au sujet de la traduction. Sous l’influence de Warren Weaver dans sa qualité de directeur de la fondation Rockefeller, la première démonstration d’une traduction complètement automatique de 60 phrases russes en anglais a eu lieu en janvier 1954. Le développement a été conduit par l’Université de Georgetown, ensemble avec IBM.

La même année, les premieres recherches en traduction automatique ont débuté en URSS. Elles se distinguaient des recherches américaines par leur caractère théorique et le choix d’une méthode faisant appel a une langue intermédiaire. Aussi bien du côté américain que du côté russe, la traduction automatique était une arme de la guerre froide. Mais le développement de la traduction automatique ne progressait pas comme prévue et au début des années 1960 les crédits publics de recherche investis dans ce domaine ont été sensiblement réduits des deux côtés.
Retournons au Luxembourg. La Haute Autorité de la CECA fusionnait en 1965 avec les commissions de la Communauté économique européenne (CEE) créée en 1957, puis en 1967 avec la Communauté européenne de l’énergie atomique (Euratom), sur base du traité de fusion des exécutifs des trois communautés. En janvier 1969 l’Office des publications officielles des Communautés européennes, devenu en 2009 l’Office des publications de l’Union européenne, a été créé et domicilié à Luxembourg. L’Office des publications publie quotidiennement le Journal officiel de l’Union européenne dans les 23 langues officielles de l’Union et propose plusieurs services en ligne destinés et aux professionnels et au grand public du monde entier. Dans son rapport d’activités des années 1975 à 1977, la Direction Générale XIII de la Commission Européenne, en charge de la gestion de l’information et de l’innovation, dont le siège se trouvait également à Luxembourg, annonçait le démarrage d’un projet pilote de traduction automatique avec le logiciel SYSTRAN.
Pendant des dizaines d’années, la DG XIII et l’Office des Publications ont été le moteur de la traduction automatique au Luxembourg.
Systran
Le logiciel SYSTRAN a été développé par Peter Toma, né en juillet 1924 à Doboz, un petit village hongrois. Marqué par les misères de la deuxième guerre mondiale, il était persuadé que les barrières linguistiques constituaient un frein pour garantir la paix. Il voulait y remédier et apprenait le russe et l’anglais, à côté de l’hongrois et de l’allemand. Après avoir immigré aux Etats-Unis en 1952, il a travaillé à partir de 1956 comme assistant à l’Institut de technologie de Californie (Caltech). Lorsqu’un ordinateur Datatron 205 a été installé à l’Institut, il espérait pouvoir réaliser son rêve d’enfant: programmer une machine pour traduire un texte en plusieurs langues. Mais les premières tentatives n’étaient pas concluantes et il quittait le Caltech en 1957. Après quelques expériences auprès de firmes privées, il joignait en mars 1959 l’Université de Georgetown pour participer aux travaux du groupe GAT (General Analysis Technique), rebaptisé dans la suite Georgetown Automatic Translation, sur un ordinateur IBM 705. Le chef de projet était Michael Zarechnak. Il est le coauteur du livre Machine Translation publié en 1979. Peter Toma dirigeait une équipe de programmeurs qui réalisait un projet surnommé SERNA. Quand il quittait l’université en 1961, il présentait SERNA comme son invention, ce qui est contesté par ses pairs de l’époque.

Peter Toma a été engagé ensuite par la société Computer Concepts à Los Angeles où il valorisait son savoir-faire pour réaliser les projets AUTOTRAN et TECHNOTRAN qui tournaient sur des ordinateurs IBM 7090. Bien que basée toujours sur des règles algorithmiques, la conception de ces programmes était complètement différente de celle du projet SERNA. En 1964 Peter Toma présentait les systèmes de traduction automatiques à des scientifiques européens à l’Université de Bonn en Allemagne. Le problème était toutefois que l’ordinateur IBM 7090 ne disposait pas de mémoire et de puissance de calcul suffisantes pour traduire plus que des courtes phrases.
Lors du vol vers l’Allemagne, Peter Toma avait lu le manuel d’instruction du nouvel ordinateur 360, annoncé par IBM. D’emblée il était persuadé que cet ordinateur permettait de réaliser vraiment ses rêves et il concevait dans sa tête l’idée comment transformer AUTOTRAN et TECHNOTRAN dans un nouveau produit qu’il nommait SYSTRAN. Comme l’environnement de travail était plus propice en Europe qu’aux Etats-Unis pour progresser avec la traduction automatique, Peter Toma décidait de rester en Allemagne. Il commençait à enseigner la programmation à l’université de Bonn, puis à l’Université de la Sarre. En parallèle, il émulait le fonctionnement de l’ordinateur IBM 360 sur le modèle IBM 7090 pour créer un modèle SYSTRAN embryonnaire. En même temps il s’était inscrit comme étudiant à Bonn où il achevait son doctorat en 1970 avec une thèse sur la traduction automatique.

Lorsque Heinz Unger, le directeur du département mathématique à l’Université de Bonn, a obtenu les crédits pour l’installation et l’exploitation d’un ordinateur IBM 360 dans son institut, Peter Toma a pu montrer le fonctionnement correct de son système de traduction SYSTRAN. En 1965, la Fondation allemande pour la recherche (DFG: Deutsche Forschungsgesellschaft) avait invité les meilleurs informaticiens et linguistes allemands pour évaluer le projet SYSTRAN. Après une journée de test et de discussions, une bourse de recherche a été accordée à Peter Toma pour parfaire son système.
En 1967, le laboratoire de Rome, le centre de recherche et de développement de la Force aérienne américaine (RADC), lançait un appel d’offre pour la traduction de textes russes en anglais. Le responsable de ce projet était Zbigniew L. Pankowicz (Ziggy), un linguiste polonais et survivant du camp de concentration d’Auschwitz, qui est immigré aux Etat-Unis après la guerre. Il a été admis au temple de la renommé (Hall of Fame) du laboratoire de Rome en 2019. Peter Toma soumettait une offre pour son projet SYSTRAN qui a été retenue par le RADC, parmi des concurrents comme IBM et Thompson Ramo Wooldridge.
Ce succès a incité Peter Toma à créer sa propre société en 1968 pour continuer le développement de SYSTRAN, à La Jolla en Californie, sous le nom de Latsec (Language translation system and electronic communications). D’autres contrats ont été conclus avec des clients américains, par exemple avec la NASA. Avec des hauts et des bas, le projet SYSTRAN a été perfectionné, à Bonn et à La Jolla, jusqu’en 1975 quand Peter Toma a fondé le World Translation Center (WTC) pour gérer les contrats SYSTRAN en dehors des Etats-Unis.
En 1973, le Danemark, l’Irlande et le Royaume-Uni ont adhéré à la Communauté économique européenne. L’introduction de l’anglais comme langue majeure et du danois comme sixième langue officielle posait la Commission Européenne et l’Office des Publications Européennes devant des problèmes monstrueux. Il fallait engager des centaines de traducteurs diplômés additionnels pour gérer le nombre grandissant de documents à publier et à distribuer. C’était le démarrage de l’introduction d’un système de traduction automatique pour les besoins des institutions européennes et le départ pour la mise en service de SYSTRAN au Luxembourg. Il existe deux récits de la manière d’adoption de SYSTRAN. Le premier récit crédite aux institutions européennes le don d’une vue à longue distance en ayant cherché pro-activement un système sur le marché. Le deuxième récit dit que c’était l’initiative de Peter Toma qui cherchait un marché européen pour son produit SYSTRAN. La vérité se trouve probablement au milieu. Il est toutefois établi que Peter Toma présentait en juin 1975 un prototype SYSTRAN anglais-français (développé par sa filiale canadienne WTC-C) à la Commission Européenne à Luxembourg et que celle-ci évaluait un deuxième produit appelé TITUS, conçu par l’Institut Textile de France. Le projet TITUS a été retiré pendant les négociations du fait qu’il ne pouvait pas traduire des textes complets. Comme SYSTRAN pouvait être utilisé sans modification sur un IBM 360, ordinateur que la Commission possédait à cette époque, un premier contrat pour l’utilisation du système SYSTRAN par les institutions européennes a été signé fin 1975 avec WTC. Il portait sur l’adaptation du projet-pilote anglais-français aux besoins de la Commission, et le développement d’un début de système français-anglais. Le chef de projet de la Commission était Loll Rolling, responsable des développements linguistiques et technologiques dans le domaine de l’information à la DG XIII, la direction générale qui gérait également le projet Euronet-Diane à l’époque.

Un des premiers contractants externes de la Commission Européenne pour le projet SYSTRAN était la société Informalux S.A. domiciliée à Rodange. Elle a été constituée en 1977 avec le slogan centre d’énergie informatique. Les actionnaires majoritaires étaient InfoArbed et la Banque Générale, Léonard Siebenaler était le directeur général.
Six traducteurs diplômés des institutions européennes ont été affectés au projet pour assister les informaticiens au développement. Après quelques mois, il ne restait qu’un seul traducteur qui faisait confiance au projet, Ian M. Pigott. Les autres étaient retournés à leurs anciens postes de travail et s’étaient solidarisés avec la majorité des traducteurs et du personnel administratif des institutions européennes qui contestait l’utilité du projet de traduction automatique. Dans la suite Ian M. Pigott a été désigné comme chef de projet SYSTRAN et il contribuait à faire évoluer le système sensiblement. Au début des années 1980 le système permettait de traduire des textes anglais en français et en italien et des textes français en anglais, avec un taux d’erreurs suffisamment bas pour faciliter la tâche des traducteurs humains à produire des traductions avec la qualité voulue. De plus en plus d’employés des institutions européennes commençaient à apprécier cet outil.
Une licence SYSTRAN a été vendu au Japon en 1980, combinée avec la création d’une société locale Systran Corporation. En juin 1982, une société luxembourgeoise Systran International GmbH a été constituée pour commercialiser le système de traduction automatique SYSTRAN. Le registre de commerce et des sociétés luxembourgeois nous renseigne que les 500 parts de la société étaient détenues par le professeur universitaire allemand Helmut Fischer (495 parts) et l’informaticien Cay-Holger Stoll (5 parts), résidant à Gonderange. Ce dernier était membre de l’équipe projet SYSTRAN comme linguiste et figurait comme gérant de la nouvelle société qui a cessé ses activités en 1987.
En 1983, InfoArbed et Informalux ont créé la joint-venture ECAT – European Center for AutomaticTranslation s.à r.l. Chaque actionnaire détenait 2000 parts. En juillet 1984 le capital de cette société a été doublé et les 4000 nouvelles parts ont été souscrites par Systran International GmbH. Après la liquidation de cette société quelques années plus tard, la dénomination sociale de ECAT a été changé en TELECTRONICS s.à r.l. en 1991.
En février 1986, une conférence mondiale SYSTRAN a eu lieu à Luxembourg. Dans l’introduction, Peter Toma racontait pourquoi il avait demandé un faible montant pour la mise à disposition du logiciel SYSTRAN à la Commission Européenne. Il soulignait que son principal objectif était le maintien de la paix et qu’une meilleure communication entre les pays européens, grâce à la traduction automatique, constituait un moyen pour y parvenir. Il annonçait également qu’il avait vendu récemment l’ensemble de ses sociétés et des droits et licences SYSTRAN (à l’exception de la filiale japonaise) à un fabricant de robinets industriels en France, la famille Gachot, qui souhaitait diversifier ses activités. Avec les revenus de cette vente Peter Toma comptait organiser deux projets de taille dans l’intérêt du maintien de la paix. Le premier projet était l’organisation d’un symposium international au sujet de la résolution de conflits prévu le 28 octobre 1986 à l’Université d’Otago en Nouvelle-Zélande. Le deuxième projet était la création de l’université internationale Aorangi privée à Dunedin en Nouvelle-Zélande. Le symposium a effectivement eu lieu, toutefois une année plus tard que révue, du 26.10 au 5.11.1987. Quant à l’université privée, la seule référence que j’ai trouvé est le nom marqué sur le brevet européen accordé à Peter Toma pour son application SYSTRAN. C’est le premier brevet accordé dans le domaine de la traduction automatique. En 1997, on retrouve Peter Toma avec une contribution My First 30 Years with MT où il figure comme président de Voxtran Inc, avec une adresse en Allemagne. Il est décédé en 2010, la même année où la mise hors service de SYSTRAN auprès des institutions européennes a eu lieu.
Il est temps de retourner en Europe. En 1986, le siège sociale de Systran a été transféré à Paris et la gestion de la société mère Systran S.A. a été assurée par Jean Gachot. Son fils Denis Gachot était déménagé en Californie pour diriger les filiales Latsec et WTC à La Jolla. En 1989, Denis Gachot a présenté The SYSTRAN Renaissance avec l’annonce de plusieurs nouveautés, entre autres des versions SYSTRAN pour PC, la location du logiciel SYSTRAN, l’accès à distance par Telenet et même un accès Minitel pour le grand public en France.

Malgré ces innovations, la réussite financière n’était pas au rendez-vous pour la famille Gachot. En 1993 les activités SYSTRAN ont été cédées à quelques anciens actionnaires minoritaires, parmi eux Dimitrios Sabatakakis qui dans la suite a dirigé le groupe Systran pendant vingt ans.
En 1996 l’équipe de développement et de maintenance SYSTRAN à Luxembourg, composée de linguistes, traducteurs et informaticiens, était passée de deux personnes à une quarantaine. La Commission Européenne planifiait de confier l’exploitation du système au Centre de traduction des organes de l’Union Européenne (CdT) qui a été établi à Luxembourg en 1994. Le CdT n’est pas attaché à la Direction Générale Traduction de la Commission Européenne, mais il dispose de sa propre personnalité juridique. Dans ce contexte le député européen Ben Fayot avait posé la question écrite E-2286/96 à la Commission au sujet de l’obligation morale d’incorporer l’équipe SYSTRAN dans le CdT. La Commission précisait que le personnel était mis à disposition par des firmes privées depuis vingt ans, sous contrats temporaires renouvelés, et que le recrutement d’agents relevait de la seule compétence du CdT.
En mars 1996, une société TELINGUA s.à r.l. a été constituée par Telindus, probablement dans le contexte du remaniement des contrats par les institutions européennes. En septembre 1997 cette société a été convertie en société anonyme Systran Luxembourg par les actionnaires Systran S.A. France (250 parts), Telindus (175 parts), Norbert von Kunitzki (50 parts) et Piere Musman (25 parts). Le contrat SYSTRAN avec la Commission Européenne a été cédé à Systran Luxembourg.
Au niveau international, le groupe Systran avait réussi à décrocher des contrats auprès de plusieurs clients prestigieux comme la NASA, Ford, Price Waterhouse Coopers, Xerox. En décembre 1997, Digital Equipment Corporation et Systran S.A. avaient lancé le premier service de traduction automatique sur le web, AltaVista Translation Service, au surnom de Babelfish. Les langues française, allemande, italienne, espagnole, portugaise et anglaise ont été supportés. Jusqu’en 2007 le service Google Translate était également basé sur le système SYSTRAN.
Au Luxembourg les sociétés Informalux S.A. et Telectronics s.à r.l. ont fusionné en 2001 la nouvelle entité a été dénommée TELECTRONICS S.A. Elle est restée active pendant presque vingt ans et a été absorbée par Proximus Luxembourg S.A. en 2020.
En 2004 Pierre Musman est sorti du Conseil d’Administration de Systran Luxembourg S.A. et Norbert Kunitzki est décédé en 2005 suite à une chute dans les montagnes. A partir de ce moment Systran Luxembourg a été administré uniquement par Denis Gachot et par Dimitrios Sabatakakis (PDG de Systran S.A France). Guillaume Naigeon de Systran S.A France assurait la fonction de commissaire aux comptes.
En 2013 la société coréenne SLCI a lancé avec succès une offre publique d’achat (OPA) pour acquérir Systran. Avec l’obtention de 85% des actions de Systran par SLCI, l’acquisition a été conclue à Seoul en mai 2014. Les administrateurs français ont quitté la société Systran Luxembourg S.A. et ont été remplacés par les administrateurs coréens Ji Changjin, Kim Dong Pil et Park Ki-Hyun.

Pendant une année Chang-Jin Ji et Guillaume Naigeon assuraient l’intérim de PDG. En juillet 2015, Jean Senelart, un ingénieur et informaticien linguistique de renom, a pris les rênes du groupe Systran. Il avait rejoint Systran en 1999, d’abord comme chef de projet, ensuite comme directeur des équipes R&D, avec lesquelles il avait lancé quatre générations de produits SYSTRAN. En 2008 il est devenu Chief Scientist et en 2014 Global CTO du groupe. Mais le jeu des chaises musicales n’était pas encore fini. En août 2020, la majorité des actions du groupe Systran a été achetée par un consortium d’investisseurs institutionnels coréens: STIC Investments, SoftBank Korea, Korea Investment Partners et Korea Investment Securities. La présidence et direction du groupe ont été confiées en mai 2022 à Vincent Godard. De formation ingénieur, il avait occupé le poste de Directeur Commercial de 2009 à 2013 auprès de Systran, ce qui facilitait sa prise de fonction. Jean Senelart continue de siéger au Conseil d’administration de Systran en tant que conseiller scientifique.
En 2022 Systran Luxembourg S.A. est administrée complètement par Systran S.A. France, le commissaire aux comptes est la société luxembourgeoise F.C.G. S.A. La filiale luxembourgeoise et la maison mère semblent se porter bien. Systran est toujours considéré comme pionnier et leader du marché de la traduction automatique, avec des technologies basées sur l’intelligence artificielle très innovantes.
Litige Systran – Commission Européenne
Une épisode dans l’histoire farfelue de Systran au Luxembourg s’est déroulée en dehors des activités techniques et commerciales et mérite d’être racontée. Comme les institutions européennes ne pouvaient pas conclure des contrats de longue durée avec des firmes privées pour la mise à disposition de personnel spécialisé en linguistique et en informatique, ces spécialistes ont été transférés tous les quelques années à une autre entreprise qui signait un nouveau contrat. Comme le groupe Systran faisait partie d’une façon ou d’une autre de ces différents contractants, il y avait toujours moyen de régler des problèmes éventuels au niveau des licences SYSTRAN.
Tout changeait lors d’un appel d’offre lancé en octobre 2003 par les institutions européennes sans la prise en compte des intérêts du groupe Systran. L’appel d’offres at été remporté par la société luxembourgeoise Gosselies S.A. qui n’avait aucune expertise en matière de linguistique informatique. La société anonyme Gosselies a été constituée en 1994 et liquidée en 2011. Dans un article du Lëtzebuerger Land du 23.12.2010, la journaliste Sophie Mosca estimait que le fait que le ministre luxembourgeois de l’Économie de l’époque, Henri Grethen, était actionnaire de Gosselies et que son épouse assurait la gestion, avait pesé dans ce choix. Ce contrat a incité la société Systran S.A. France et sa filiale luxembourgeoise à déposer de suite une plainte pour violation des droits d’auteur contre la Commission Européenne. Ce n’est qu’en janvier 2007 que le groupe Systran a réussi à introduire une action en réparation devant la Cour de Justice Européenne. Et il fallait attendre presque 3 ans jusqu’à la réception d’une réponse. Le 16 décembre 2010 le Tribunal de l’union européenne a condamné la Commission à verser au groupe Systran une indemnité forfaitaire de 12 001 000 euros. C’était une première. Le PDG de Systran Dimitrios Sabatakakis s’est félicité et tirait son chapeau à la justice européenne. Mais il s’était réjoui trop tôt. Deux mois plus tard la Commission Européenne a introduit un pourvoi dans ce litige. Et comme les rouages de la justice sont lents, ce n’est que le 18 avril 2013 que la Cours de Justice européenne a annulé son jugement antérieur et qu’elle a renvoyé l’affaire devant les tribunaux nationaux.
Il semble que dans la suite un arrangement à l’amiable a été négocié en 2017 entre les institutions européennes et le groupe Systran et qu’une somme de quelques millions euros a été versée à Systran comme dédommagement. Cette transaction était à l’origine d’un autre procès judiciaire, cette fois entre la société coréenne SLCI et les anciens actionnaires de Systran. Les conditions de l’OPA, finalisée en 2014, stipulaient que SLCI devait reverser aux vendeurs des actions une partie d’une éventuelle indemnisation par la Commission Européenne. Comme SLCI, respectivement ses héritiers, avaient manqué à cette obligation, l’affaire s’est terminée devant les tribunaux. Le complément de prix dû aux anciens actionnaires a été payé en mars 2020.
Cette épisode termine mon récit sur l’histoire de Systran durant un demi-siècle. Dans les prochains chapitres nous allons découvrir les autres projets de traduction automatique qui touchent le Luxembourg et qui ont également une histoire passionnante. Il reste à souligner que même en 2022 Systran continue à traduire bise en Kuss au lieu de Nordwind.
EUROTRA
Lors de la mise en place de SYSTRAN en 1976, il n’y avait pas seulement de la résistance auprès du personne des services de traduction des institutions européennes, mais également beaucoup de critiques de la part de linguistes dans les universités en Europe qui reprochaient à la Commission Européenne d’acheter un produit américain au lieu de promouvoir le savoir-faire européen. Le directeur général de la DG XIII, Raymond Appleyard, et le directeur responsable pour la gestion de l’information à la DG XIII, Georges J. Anderla, étaient sensibles à ces arguments et proposaient le lancement d’un projet européen de traduction automatique, tout en continuant à supporter la solution pragmatique SYSTRAN. Le projet, appelé EUROTRA, n’a été approuvé qu’en 1982 par le Conseil Européen et par le Parlement Européen et il n’a démarré qu’en 1985. Malgré un investissement de 70 millions euros pendant 10 ans, le système n’est jamais devenu opérationnel. Bryan Oakley a expliqué les raisons de cet échec dans sa contribution To Do the Right Thing for the Wrong Reason; the EUROTRA Experience.
MT@EC
Le nombre de paires de langues supportées par SYSTRAN ne cessait de croître, mais le travail lexicographique sous-jacent rendait difficile l’extension de la couverture aux nouvelles langues résultant des élargissements successifs de l’Union européenne. En décembre 2010 le système SYSTRAN a été arrêté et remplacé en 2013 par MT@EC, un système de traduction automatique basé sur les statistiques et exploitant les énormes corpus bilingues et multilingues des institutions européennes tels qu’Euramis. S’appuyant sur le système à source ouverte Moses, développé à l’Université d’Edimbourg, MT@EC supportait en 2016 plus que 500 paires de langues, avec des degrés divers de fiabilité et de qualité. Mais la durée de vie du projet MT@EC était largement inférieure à celle de SYSTRAN, le système a été rapidement remplacé par eTranslation.
eTranslation
Comme la technologie de l’intelligence artificielle se développait à un rythme stupéfiant, la méthode de traduction automatique fut surpassée par une nouvelle méthode dès 2017. La traduction automatique neuronale était arrivée, rendue possible par les progrès en matière de puissance de calcul faisant sortir l’intelligence artificielle des laboratoires. Cette nouvelle technologie exigeait encore davantage de puissance de calcul, et plus spécifiquement, des processeurs graphiques. Testé depuis 2019, un nouveau service en ligne appelé eTranslation a été ouvert en mars 2020, non seulement pour les institutions européennes, mais également pour les entreprises européennes et pour des professionnels, et ceci à titre gratuit. Markus Foti est le responsable de ce projet.
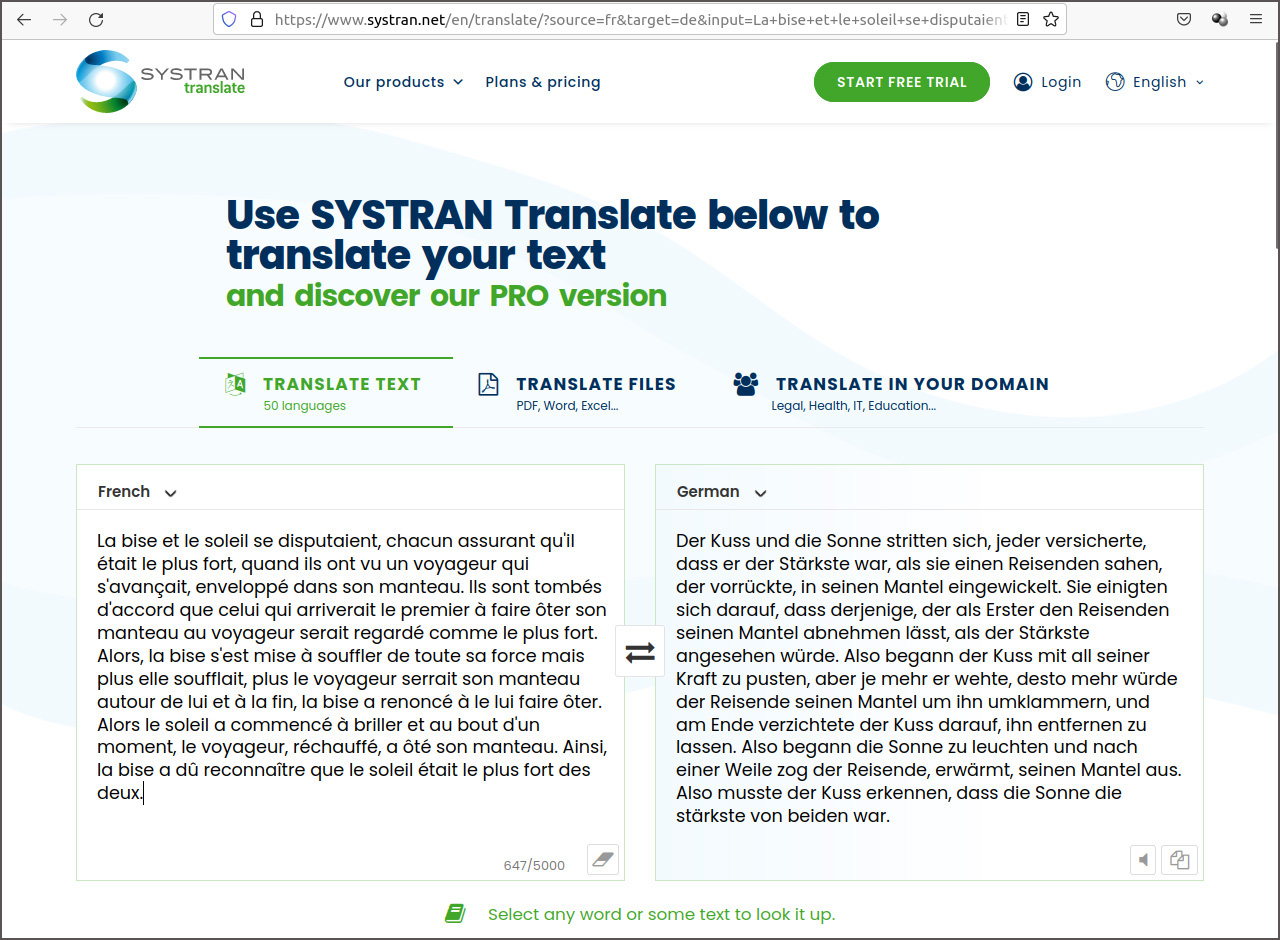
J’ai testé le service eTranslate avec la traduction française-allemande de la phrase “La bise et le soleil …”. eTranslate propose 3 termes différents pour traduire la bise en fonction du contexte: der Kuss, die Knie et der Bise. Le modèle de traduction utilisé pour eTranslate ne semble donc pas encore être à la hauteur de ses compères Google, Facebook ou IBM. Une copie écran et le texte traduit complet sont affichés ci-après:
Der Kuss und die Sonne stritten, und jeder versicherte, er sei der Stärkste, als sie einen Reisenden sahen, der in seinem Mantel vorrückte. Sie waren sich einig, dass derjenige, der es als Erster schafft, dem Reisenden seinen Mantel ausziehen zu lassen, als der Stärkste angesehen wird. So begann der Kuss mit seiner ganzen Kraft zu blasen, aber je mehr sie wehte, desto mehr würde der Reisende seinen Mantel um ihn spannen, und am Ende verzichtete die Knie darauf, ihn zu entfernen. Dann fing die Sonne an zu leuchten und nach einer Weile zog der Reisende, der erwärmte, seinen Mantel aus. So musste der Bise erkennen, dass die Sonne die stärkste von beiden war.
Si vous souhaitez traduire des textes étrangers en luxembourgeois, c’est en vain. La langue luxembourgeosie n’est pas encore supporté. Il faut s’adresser à Google Translate.
Google Translate
Le service de traduction en ligne Google Translate a été lancé en avril 2006. Il était d’abord basé sur la technologie SYSTRAN. En octobre 2007 Google a remplacé SYSTRAN par sa propre technologie de traduction automatique statistique, supportant 25 languages. En janvier 2010 Google a introduit une version mobile pour Android, une année plus tard une application pour iOS.
Une application de réalité virtuelle pour traduire des mots ou textes, photographiés avec un smartphone ou une tablette, appelée Word Lense, a été intégrée dans Google Translate suite à l’acquisition par Google en mai 2014 de la startup américaine Quest Visual qui avait développé ce système.
En février 2016 Google avait ajouté 13 langues additionnelles à son service Google Translate, dont le luxembourgeois, pour supporter alors un total de 103 langues. Au début ce n’était pas parfait, par exemple Lëtzebuerg ass mei Land a été traduit en Irland ist mein Land.
En novembre 2016 Google a introduit la version neuronale Google Neural Machine Translation (GNMT) de son service de traduction automatique pour 40 langues. GNMT fait partie du projet Google Brain, lancé en 2011 par Jeff Dean et Greg Corrado des laboratoires de recherche Google X et par Andrew Yan-Tak Ng de l’université de Stanford. En août 2017 le nouveau système a été étendu aux autres langues et le support du luxembourgeois a été bien amélioré.
Le service Google Translate est gratuit pour des traductions en ligne de textes courts, mais c’est un service payant qui fait partie des produits Google Cloud pour des traductions de taille.
Quelques développeurs indépendants de Google publient sur la plateforme Github des logiciels permettant la traduction gratuite de documents volumineux, en contournant les barrières et restrictions intégrées dans les interfaces publics de Google Translate. Deux exemples sont les projets google-translate-php et google-trans-new.
Mon conseil est de ne pas recourir à de telles solutions qui ne sont pas fiables, illégales et qui portent le risque de voir son adresse IP bloquée par Google pour tous ses services proposés, y inclus la recherche sur le web. Il vaut mieux de passer son temps à explorer des services de traduction amusants comme Fabricius, le service en ligne de Google pour déchiffrer des hiéroglyphes. Cette application fait partie de l’espace dédié à l’Égypte ancienne au sein de sa section Google Arts & Culture, dévoilé le 15 juillet 2020 pour célébrer l’anniversaire de la découverte de la Pierre de Rosette.

Yandex Translate
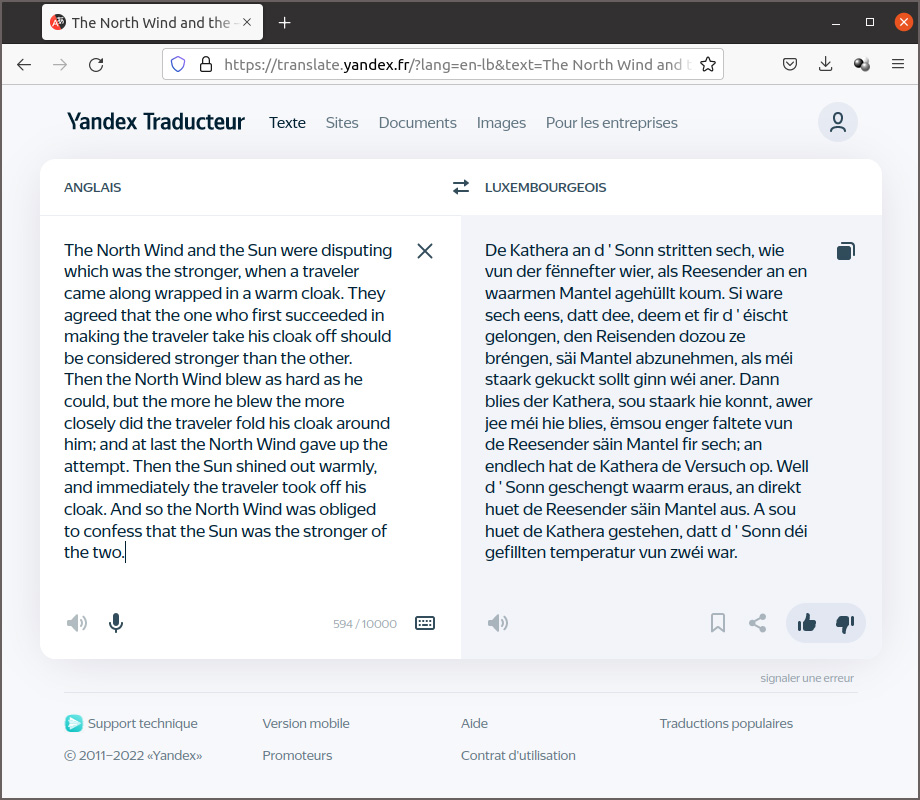
Les internautes en Russie et dans différents autres pays de l’Est préfèrent utiliser Yandex Translate au lieu de Google Translate. Le service est intégré dans le moteur de recherche de même nom créé en 1997 par Arkadi Voloj. Yandex est une socitété russe dont la maison mère est basée à Amsterdam. Yandex Translate utilise un système statistique de traduction automatique par auto-apprentissage. Ce qui surprend c’est que le service supporte la langue luxembourgeoise. Les résultats de la traduction anglais-luxembourgeois de la fable d’Esope, affichés ci-après, montrent que la qualité de la traduction n’est pas très élevée.
Dans les prochains chapitres nous allons découvrir les projets de traduction automatique à source ouverte de Systran (OpenNMT), de Microsoft (MarianNMT, de Facebook (NLLB), d’Amazon (Sockeye) et de Google (T5, mt5) .
OpenNMT
OpenNMT est le projet de traduction automatique à source ouverte le plus ancien. Yoon Kim, membre du groupe NLP de l’université de Harvard, a lancé en juin 2016 le projet seq2seq-attn sur Github qui est à l’origine du projet. Yoon Kim est aujourd’hui maître assistant au MIT. En collaboration avec Systran, un premier modèle OpenNMT a été publié en décembre 2016. L’auteur principal était Guillaume Klein de Systran. Une première version OpenNMT pour PyTorch a été publiée en mars 2017 (OpenNMT-py), en collaboration avec Facebook Research. Une version pour TensorFlow suivait en juin 2017 (OpenNMT-tf). Le projet OpenNMT est actuellement maintenu par Systran et Ubiqus. L’ancien PDG de Systran, Jean Senellart, est un des administrateurs du forum OpenNMT.
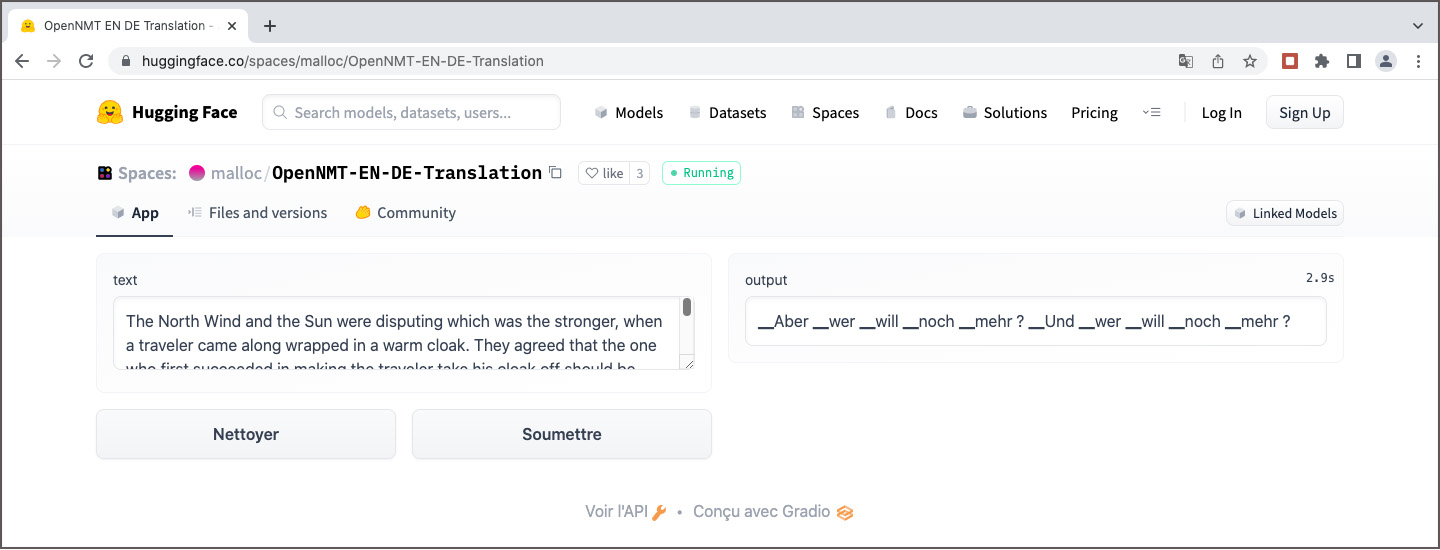
Des modèles de traduction pré-entraînés pour OpenNMT sont rares. Sur le site web OpenNMT on trouve seulement deux modèles : un modèle Transformer anglais-allemand et un modèle BiLSTM allemand-anglais. Le premier est disponible sur la plateforme huggingface.co comme espace de démonstration. J’ai essayé de l’évaluer, mais sans succès. Il semble que le fichier de configuration manque, ce qui peut expliquer la traduction farfelue.
MarianNMT
MarianNMT est un outil neuronal de traduction automatique entièrement programmé en C++. Pour cette raison il est deux fois plus rapide que OpenNMT si on effectue des tests dans les mêmes conditions. Le projet a été développé à l’Université d’Edimbourg et à l’Université Adam Mickiewicz à Poznań en Pologne, en collaboration avec Microsoft, à partir de 2017.
Le chef de projet était Marcin Junczys-Dowmunt, actuellement scientifique NLP principal auprès de Microsoft. Il est né à Bydgoszcz en Pologne, la ville natale de Marian Rejewski, un mathématicien et cryptologue polonais renommé. En hommage à ce scientifique, Marcin Junczys-Dowmunt a utilisé son prénom comme nom de travail du projet et le nom n’a jamais été changé. La technologie Marian est utilisée par Microsoft pour son service de traduction commercial Microsoft-Translator sur la plateforme Azure. A l’exemple de Google, une version légère est intégrée sans le moteur de recherche Bing de Microsoft pour traduire gratuitement des textes courts. Mais la langue luxembourgeoise n’est pas supportée par Microsoft.
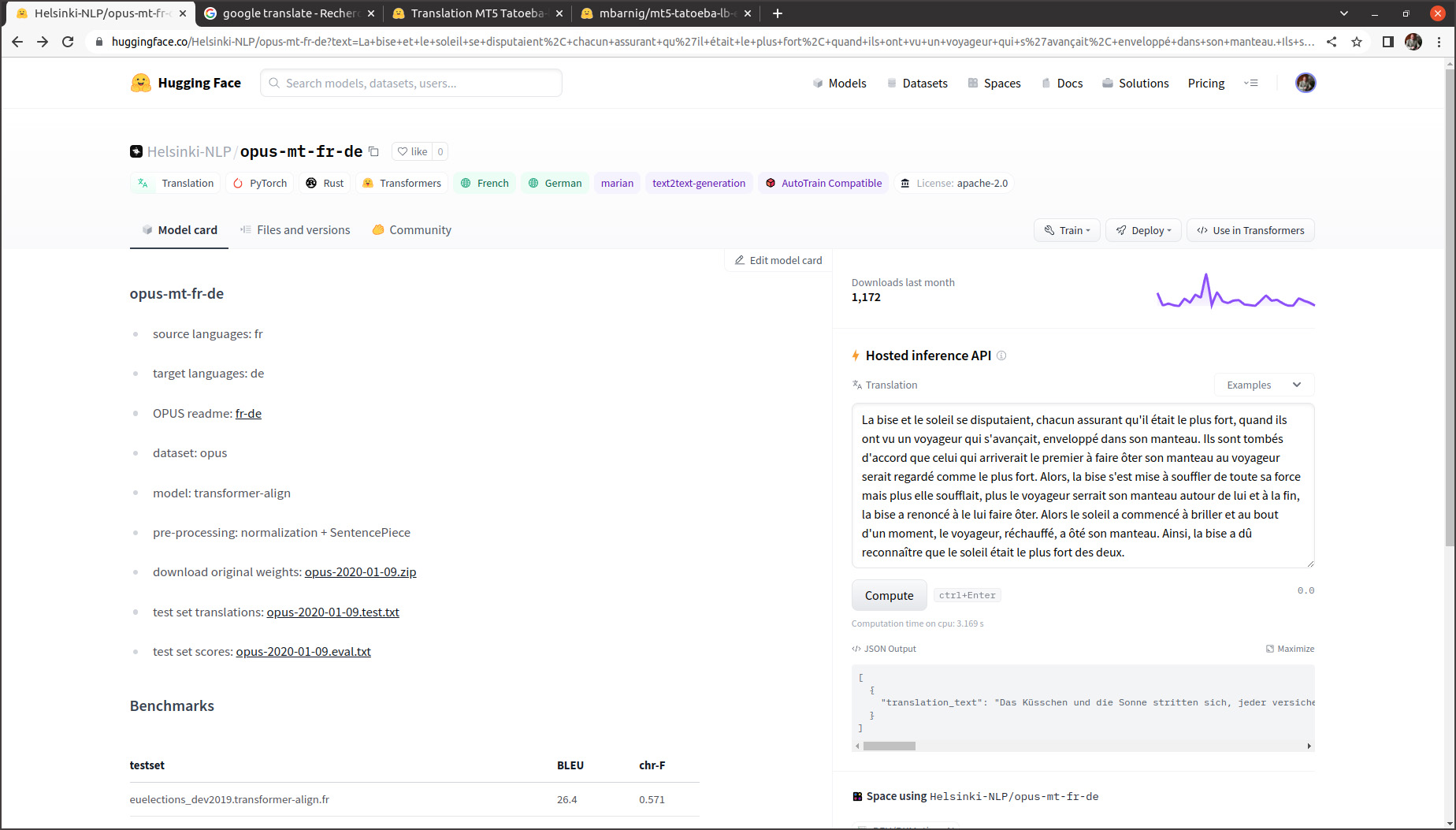
Une multitude de modèles de traduction pour différentes paires de langues a été publiée par l’Université d’Helsinki sous l’initiative de Jörg Tiedemann, professeur des technologies de language au département des humanités numériques (HELDIG). Ces modèles neuronaux sont connus sous les noms de Helsinki-NLP/opus-mt-xx-yy (xx = langue source, yy = langue cible). Ils ont été entraînés avec les données du corpus public ouvert OPUS, respectivement avec les données de la collection Tatoeba. Sur Huggingface 1.466 modèles sont disponibles, parmi eux le modèle opus-mt-fr-de qui est à l’origine du titre de la présente publication.
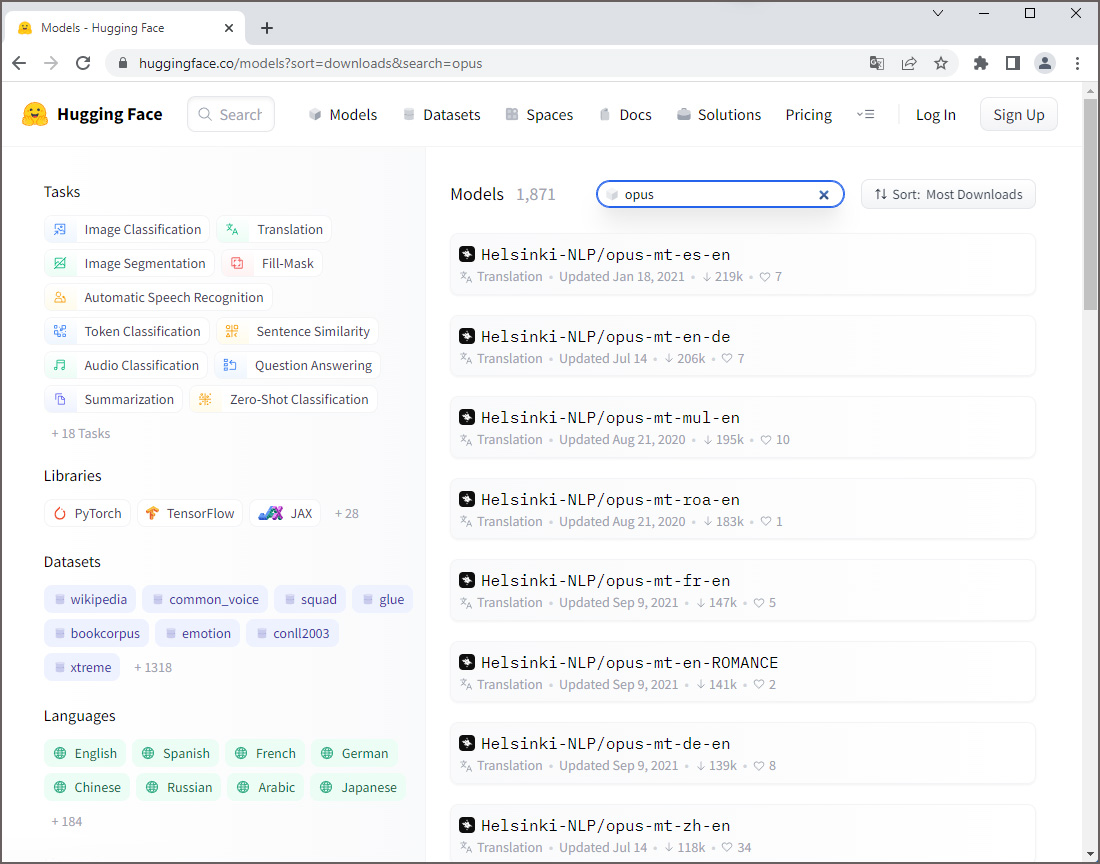
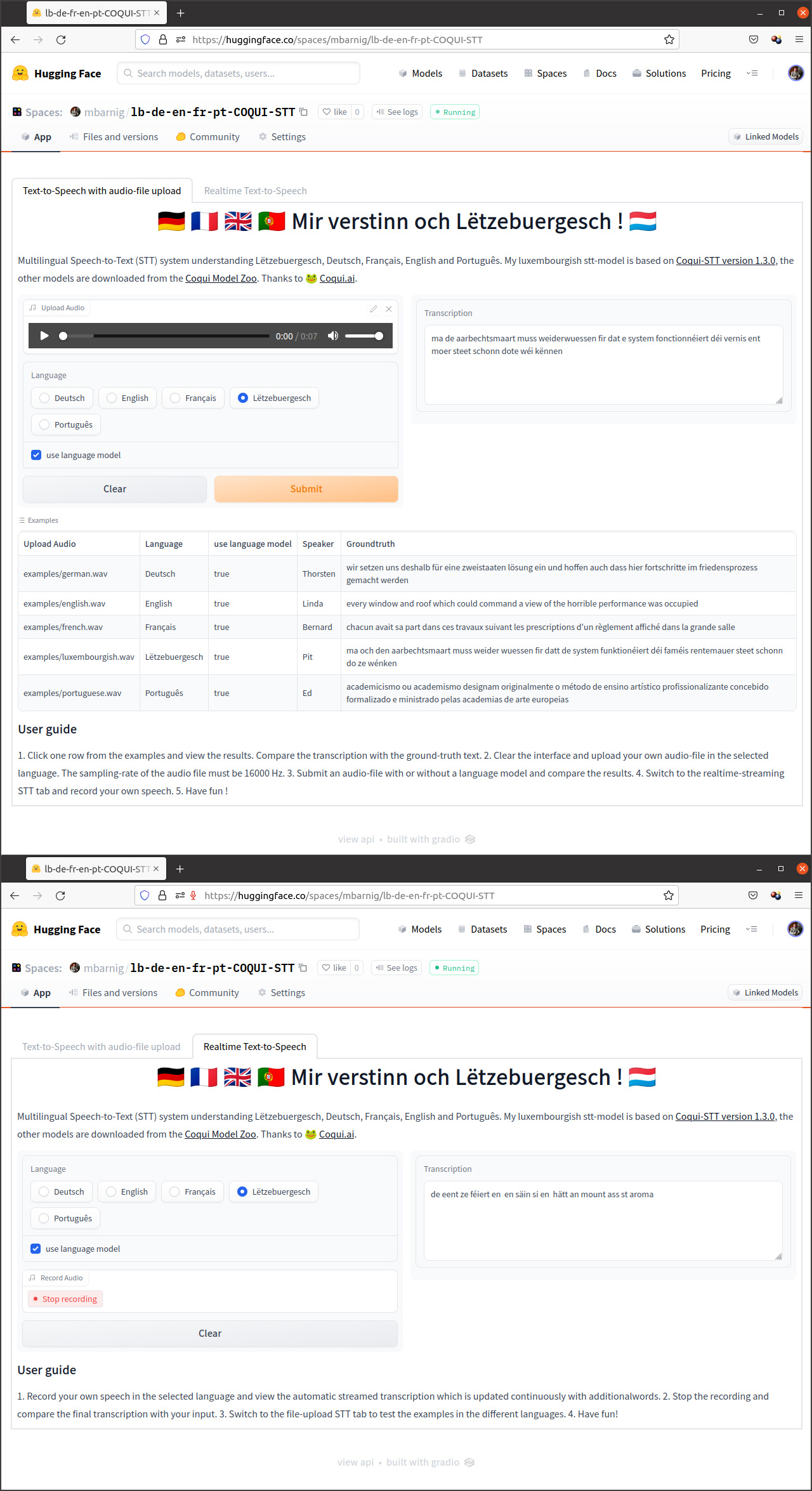
Dans la liste des modèles MarianMT entraînés moyennant le corpus Tatoeba luxembourgeois on trouve un modéle anglais-luxembourgeois et un modèle luxembourgeois-anglais. Après conversion en format PyTorch, j’ai téléchargé les fichiers afférents comme bases de données et comme modèles sur la plateforme Huggingface. J’ai programmé en outre une application pour un espace de démonstration. Hélas le corpus Tatoeba luxembourgeois n’a ni la taille ni la qualité pour obtenir des résultats de traduction valables. Dans l’attente de la découverte d’une base de données plus appropriée pour pouvoir entraîner un meilleur modèle de traduction anglais-luxembourgeois, et éventuellement des modèles luxembourgeois avec d’autres langues comme source ou cible, je laisse la présente version en place sur Huggingface comme preuve de concept.
NLLB (No Language Left Behind)
Précédé par son modèle pytorch/translate, Facebook Research a présenté en 2019 son outil de modélisation de séquences fairseq en source ouverte qui permet, entre autres, de faire de la traduction automatique. A l’instar de OpenNMT et de MarianNMT, des modèles de traduction automatique pré-entraînés pour quelques couples de langues ont été mis à la disposition des chercheurs.
En octobre 2021 Facebook Inc., la maison mère des services Facebook, Instagram, WhatsApp et Messenger, a changé son nom en Meta Platforms Inc. et Facebook AI est devenu Meta AI. Récemment, le 6 juillet 2022, Meta AI a annoncé la mise au point du premier modèle d’intelligence artificielle unique qui permet la traduction en 200 langues différentes avec une qualité de pointe. Ce modèle, appelé NLLB-200, fait partie de l’initiative No Language Left Behind de Meta. Une publication détaillée de 190 pages sur le projet est disponible sur arXiv.
Le modèle NLLB-200 est disponible en plusieurs versions, avec des tailles allant de 4,4 GB (600 millionsde paramètres) jusqu’à 404 GB (54,5 milliards de paramètres. Pour tester NLLB, on a plusieurs possibilités :
- moyennant un notebook sur Google Colab
- moyennant l’espace NLLB Translatior sur Huggingface, développé par Narrativa
- moyennant l’API de Narrativa
- moyennant la librairie Transfomers de Huggingface
- à partir du code source NLLB sur Github
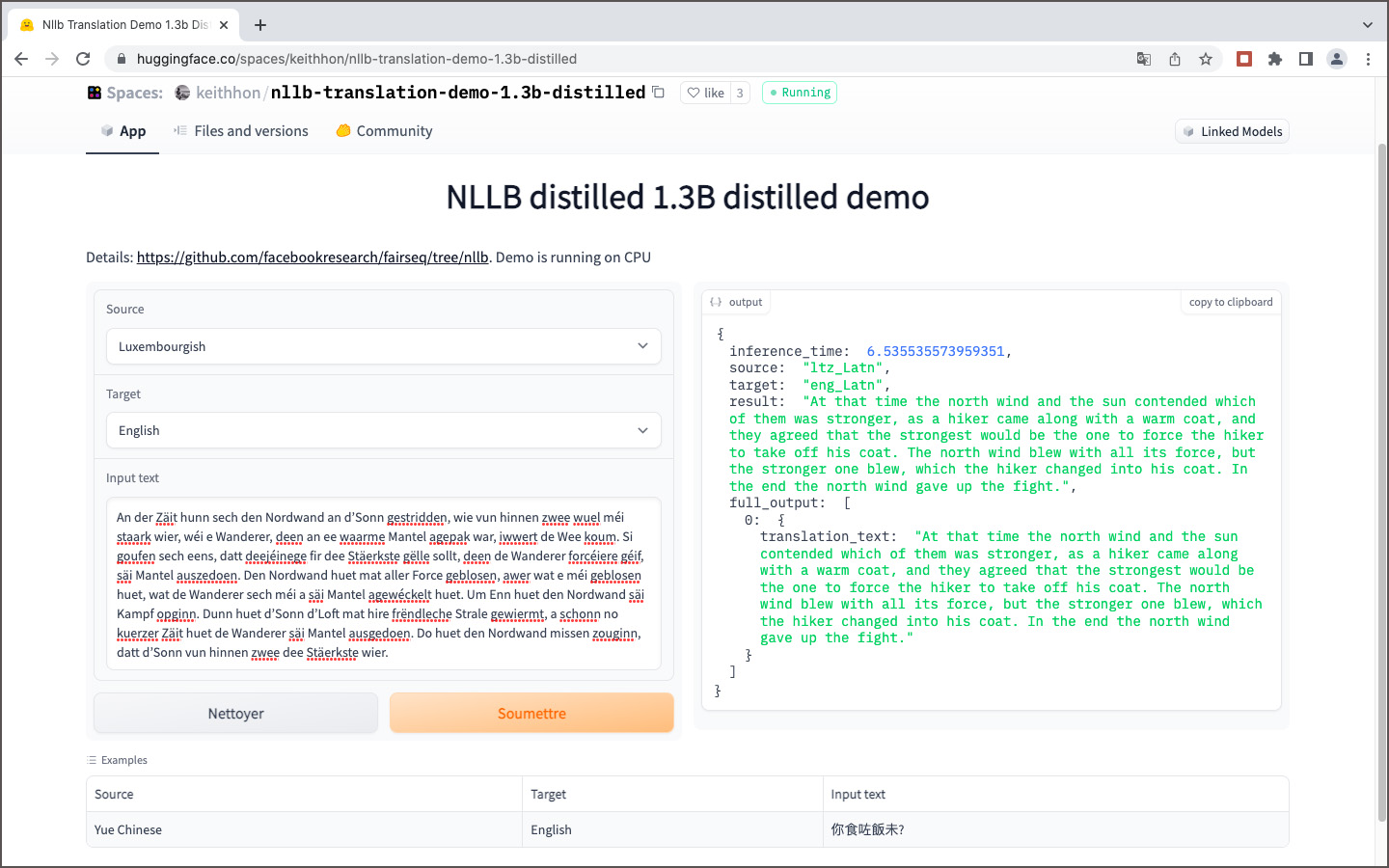
Le code Python pour traduire un texte anglais en luxembourgeois avec la librairie Transformers de Huggingface est montré ci-après comme exemple:
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-200-distilled-600M", use_auth_token=False, src_lang="eng_Latn")
model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M", use_auth_token=False)
article = "The North Wind and the Sun were disputing which was the stronger, when a traveler came along wrapped in a warm cloak."
inputs = tokenizer(article, return_tensors="pt")
translated_tokens = model.generate(**inputs, forced_bos_token_id=tokenizer.lang_code_to_id["ltz_Latn"], max_length=100)
tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
Amazon Translate et Sockeye
Le service de traduction automatique commercial de Amazon repose également sur un projet à source ouverte, appelé Sockeye, disponible sur Github. Les origines du projet remontent à 2017; plus que 70 versions ont été publiées depuis, la version la plus récente ( 3.1.14.) date du 5 mai 2022. Si on passe le test de La bise et le soleil se disputaient … au traducteur Amazon Translate, on s’étonne que la traduction allemande Der Nordwind und die Sonne stritten sich … est correcte. Mais à la deuxième vue on découvre que dans les autres phrases la bise devient der Kuss comme dans la majorité des autres systèmes de traduction.
En été 2022 la langue luxembourgeoise n’était pas encore supportée par Amazon Translate.
Google T5 et mt5
Les premiers modèles neuronaux entraînés pour la traduction automatique étaient basés sur une architecture de réseau de neurones récurrents. Tout a changé en juin 2017 lorsque Google a présenté une nouvelle architecture de réseau neuronal, appelée Transformeur, dans sa publication Attention is All You Need. D’un jour à l’autre les transformeurs, qui sont conçus pour gérer des données séquentielles telles que le langage naturel, sont devenus le modèle de choix pour la traduction automatique. Cela a conduit au développement de systèmes pré-entraînés tels que BERT (Bidirectional Encoder Representations from Transformers) par Google et GPT-1 (Generative Pre-Training Transformer) par OpenAI en 2018.
Fin 2019 Google a introduit son transformeur T5, pré-entraîné avec un vaste ensemble de données C4 (Colossal Clean Crawled Corpus), publié ensemble avec le modèle. Le modèle T5 supporte 4 langues (anglais, allemand, français et roumain) et existe en cinq versions:
- T5-Small (60 millions de paramètres)
- T5-Base (220 millions de paramètres)
- T5-Large (770 millions de paramètres)
- T5-3B (3 milliards de paramètres)
- T5-11B (11 milliards de paramètres)
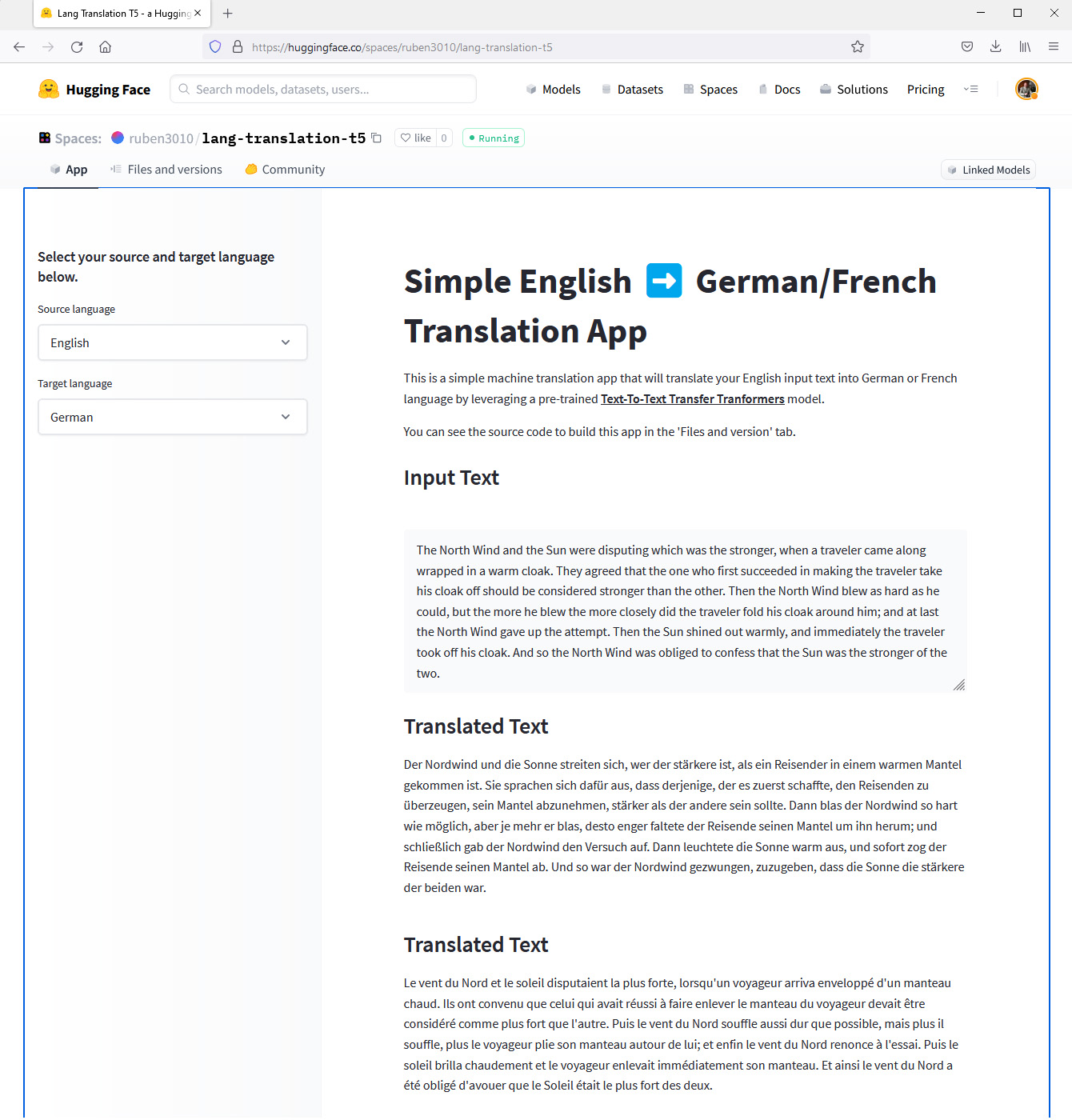
Même si l’application principale du modèle T5 n’est pas la traduction, celle-ci fonctionne entre les quatre langues supportées. Une démonstration de traduction de textes anglais en allemand ou en français est accessible sur Huggingface.
Un modèle multilingue mt5 supportant 101 langues, dont le luxembourgeois, a été présenté par Goggle une année après le modèle T5, en octobre 2020. Comme le modèle mt5 nécessite un réglage fin (finetuning) avant de pouvoir servir pour des applications de traitement du langage, comme la traduction automatique, Shivanand Roy a développé l’outil simpleT5 qui facilite l’entraînement du modèle pour une langue, ou pour un couple de langues déterminées. Un autre chercheur, Thilina Rajapakse, a développé un outil similaire appelé simpletransformers. L’auteur a mis en place un site web dédié pour SimpleTransformers et a publié la contribution How to Train an mT5 Model for Translation With Simple Transformers qui explique comment entraîner le modèle mt5 pour la traduction automatique du paire des langues anglais – cingalais.
Comme le réglage fin des modèles T5 et mt5 nécessitent des puissance de calcul et des tailles de mémoire très élevées, typiquement une TPU (Tensor Processing Unit) comme accélérateur sur Google Colab, je me suis limité à l’entraînement du modéle mt5-small qui a une taille de 1,2 GB. J’ai utilisé le corpus Tatoeba anglais-luxembourgeois pour la formation avecl le script Python affiché ci-après:
import logging
import pandas as pd
from simpletransformers.t5 import T5Model, T5Args
import torch.multiprocessing
torch.multiprocessing.set_sharing_strategy('file_system')
logging.basicConfig(level=logging.INFO)
transformers_logger = logging.getLogger("transformers")
transformers_logger.setLevel(logging.WARNING)
train_df = pd.read_csv("dataset/train.tsv", sep="\t").astype(str)
eval_df = pd.read_csv("dataset/eval.tsv", sep="\t").astype(str)
train_df["prefix"] = ""
eval_df["prefix"] = ""
model_args = T5Args()
model_args.max_seq_length = 72
model_args.train_batch_size = 10
model_args.eval_batch_size = 10
model_args.num_train_epochs = 5
model_args.evaluate_during_training = True
model_args.evaluate_during_training_steps = 30000
model_args.use_multiprocessing = False
model_args.fp16 = False
model_args.save_steps = -1
model_args.save_eval_checkpoints = False
model_args.no_cache = True
model_args.reprocess_input_data = True
model_args.overwrite_output_dir = True
model_args.preprocess_inputs = False
model_args.num_return_sequences = 1
model_args.wandb_project = "MT5 Luxembourgish-English Translation"
model = T5Model("mt5", "google/mt5-small", args=model_args)
# Train the model
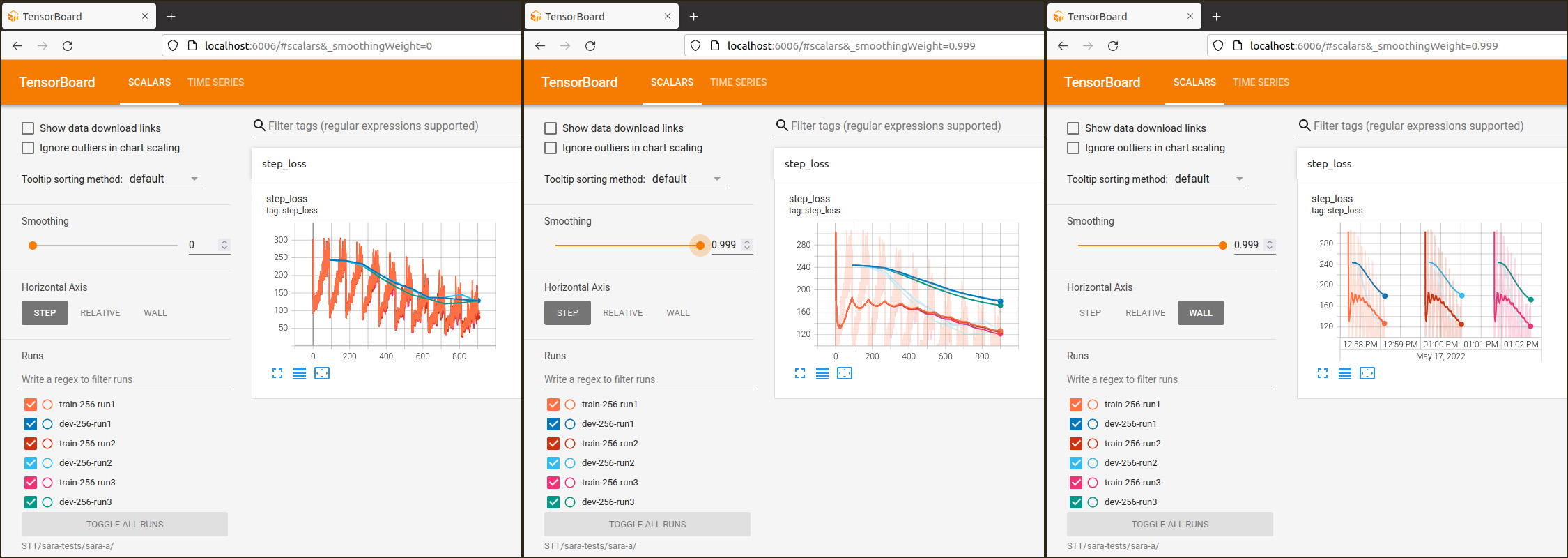
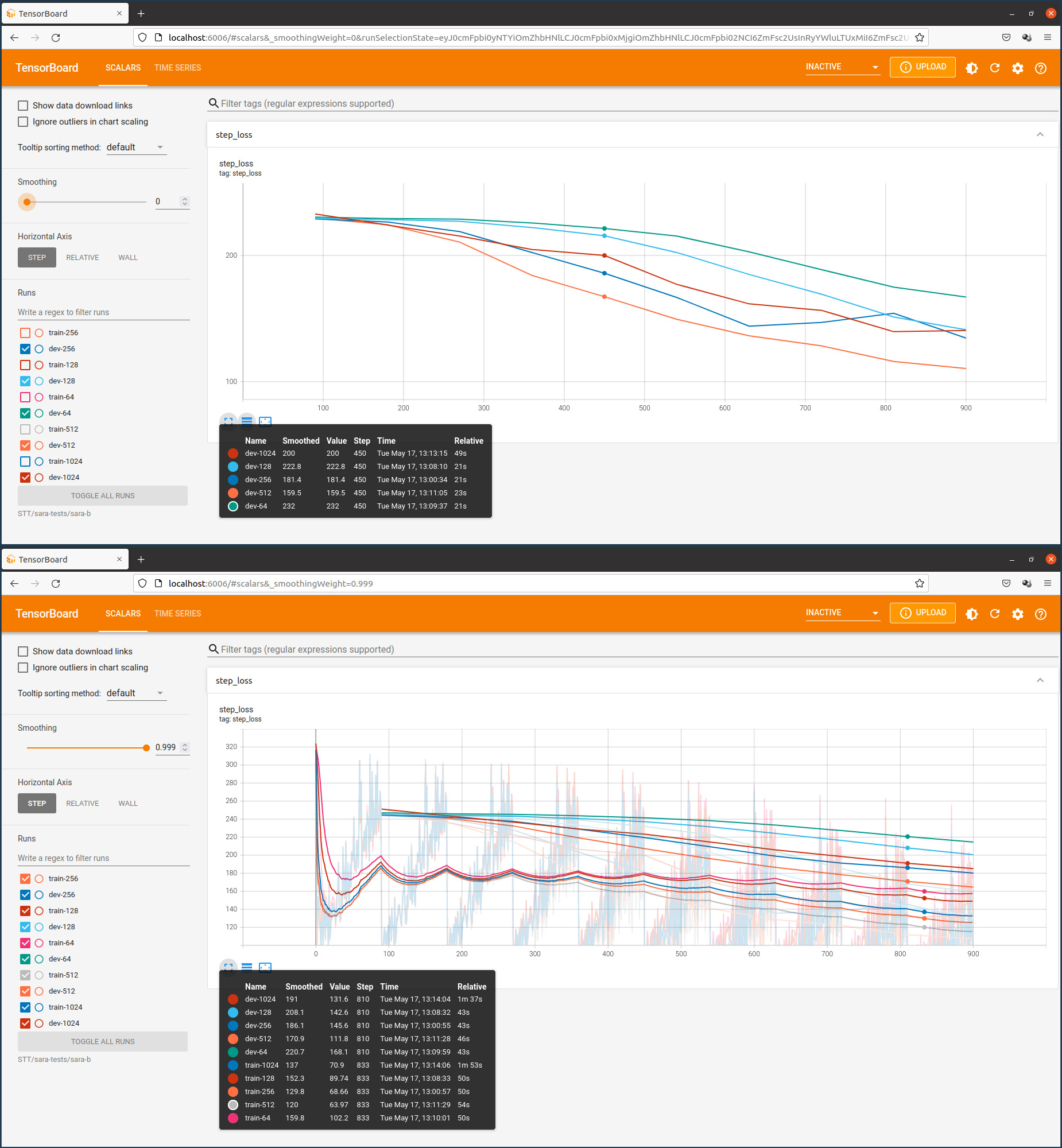
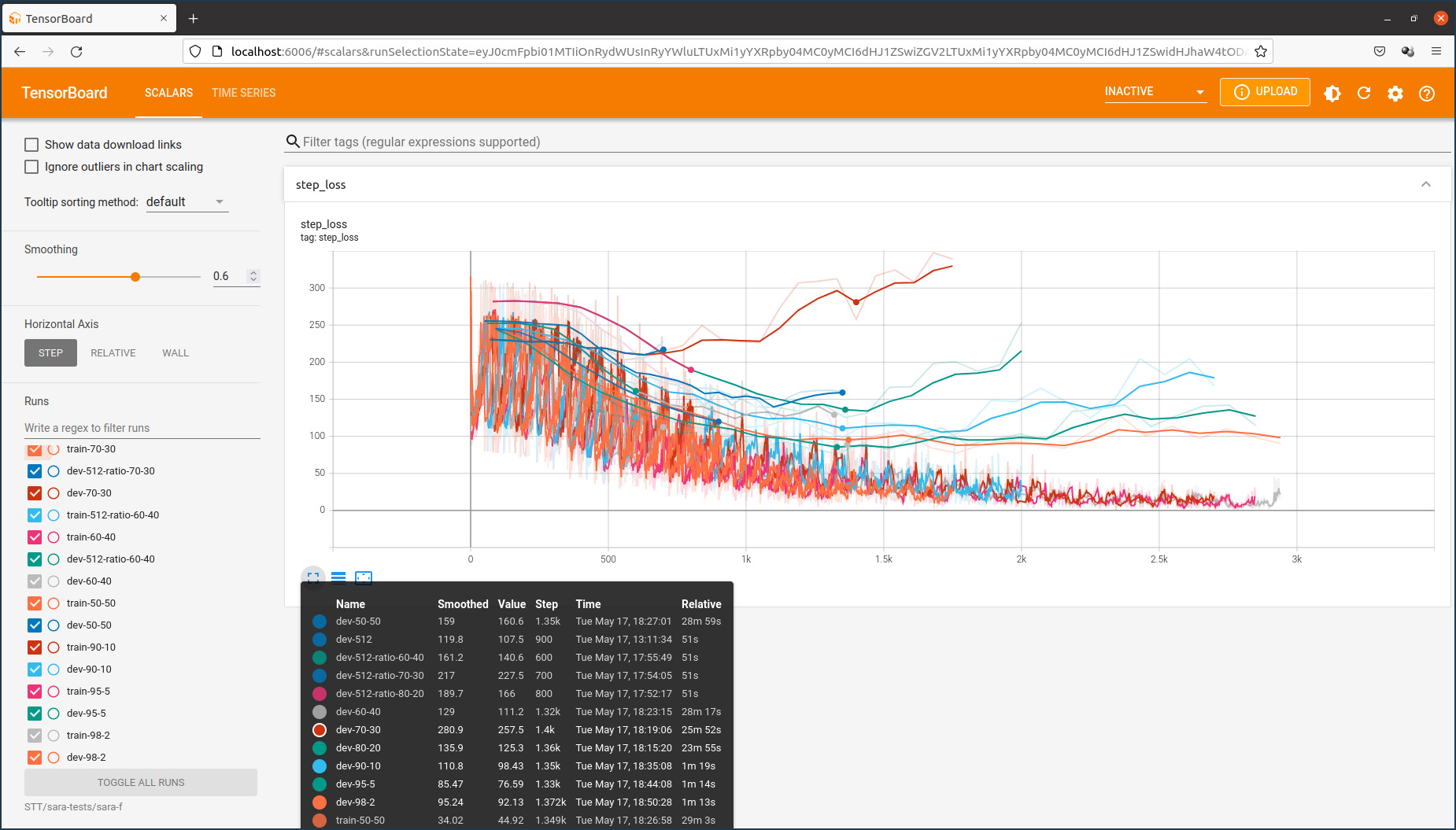
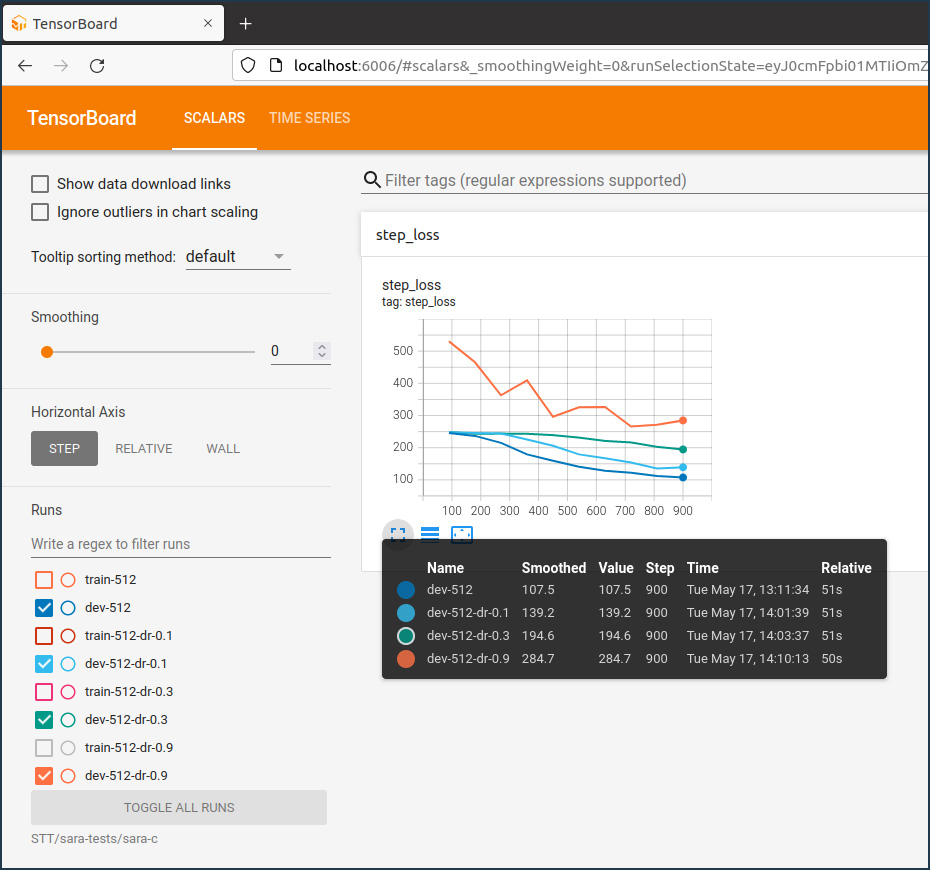
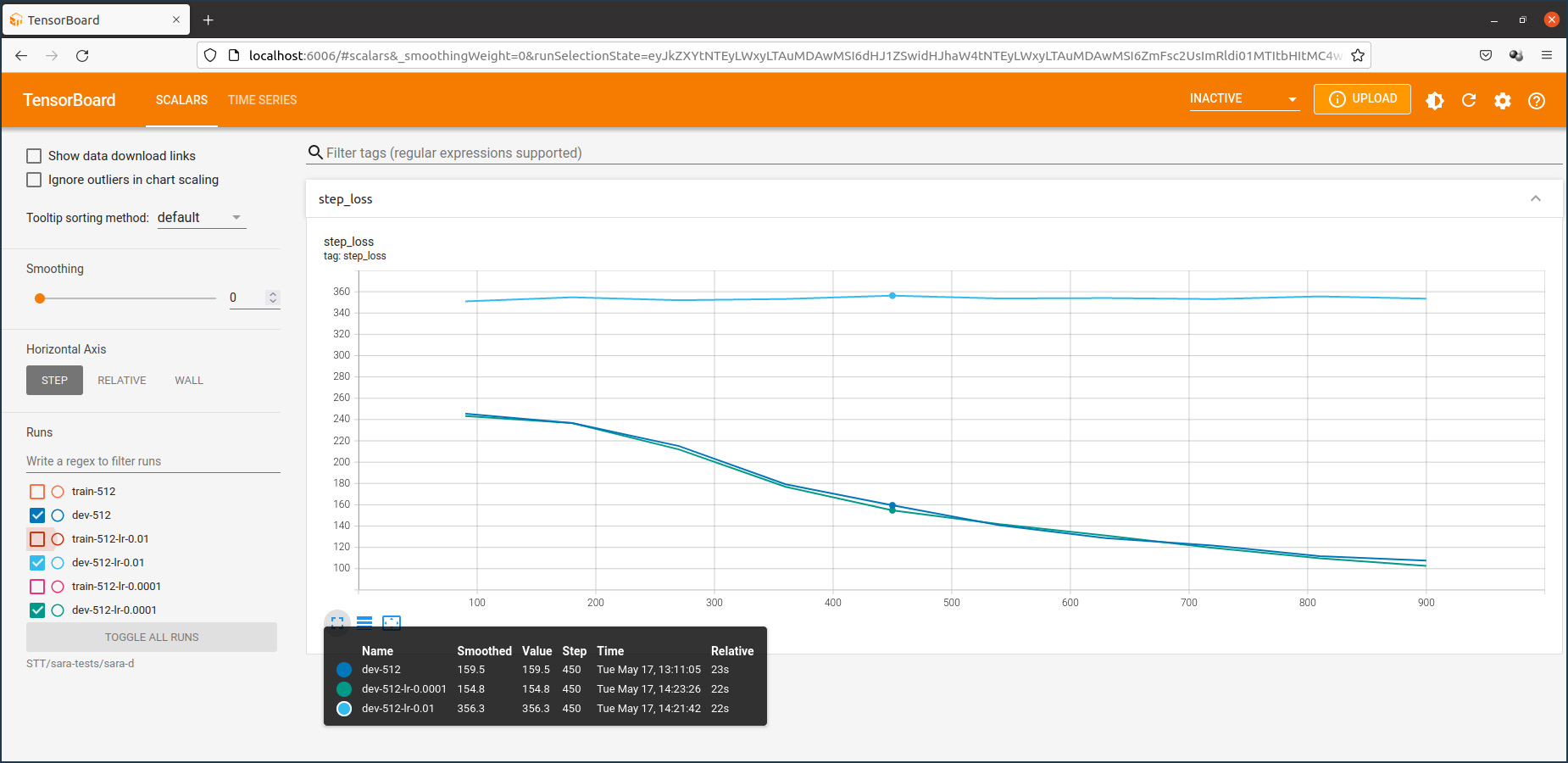
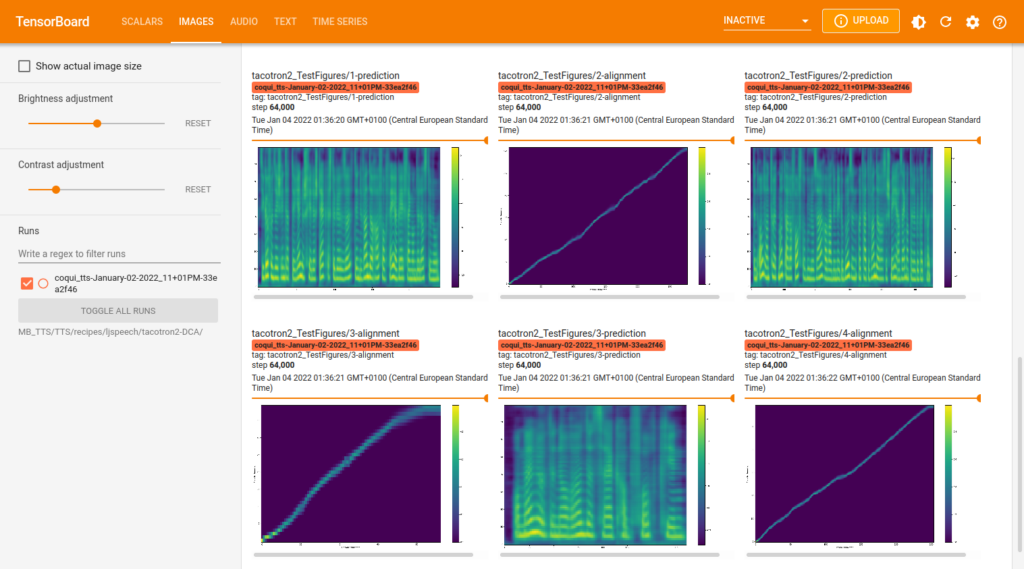
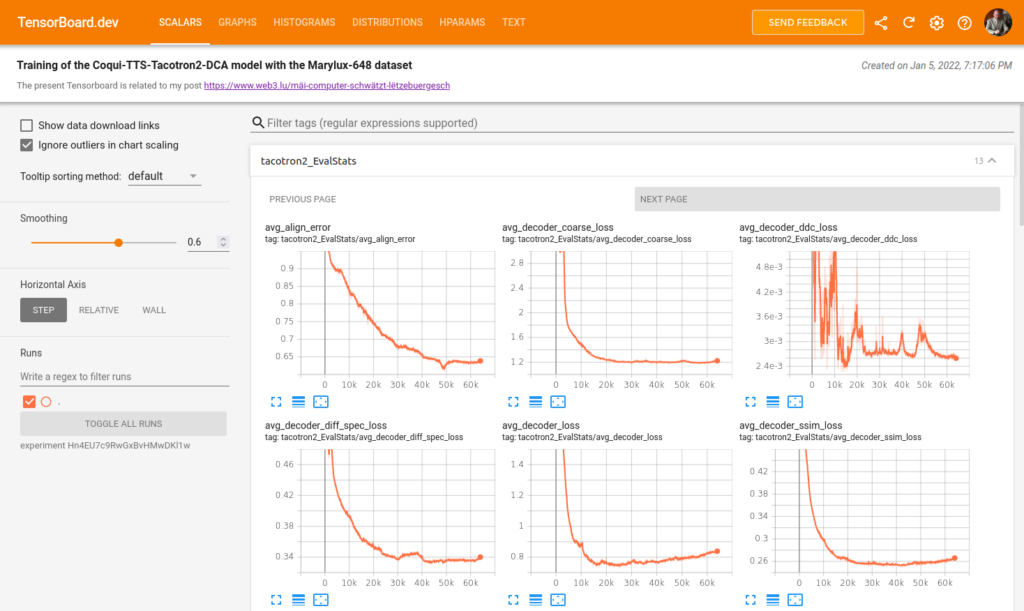
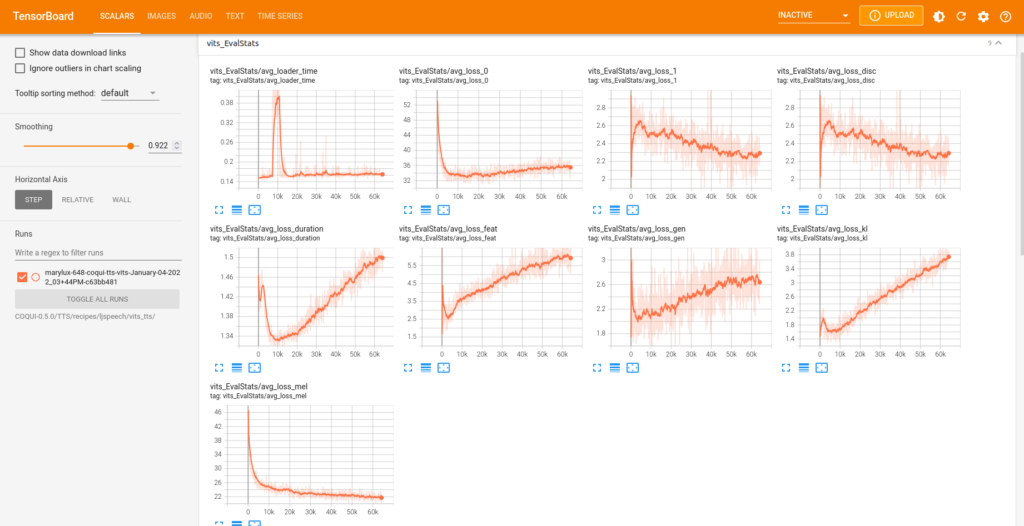
model.train_model(train_df, eval_data=eval_df)Le graphique enregistré sur la plateforme Weights & Biases qui suit montre l’évolution des scalaires pendant l’entraînement dont l’objectif principal est de minimiser les pertes.
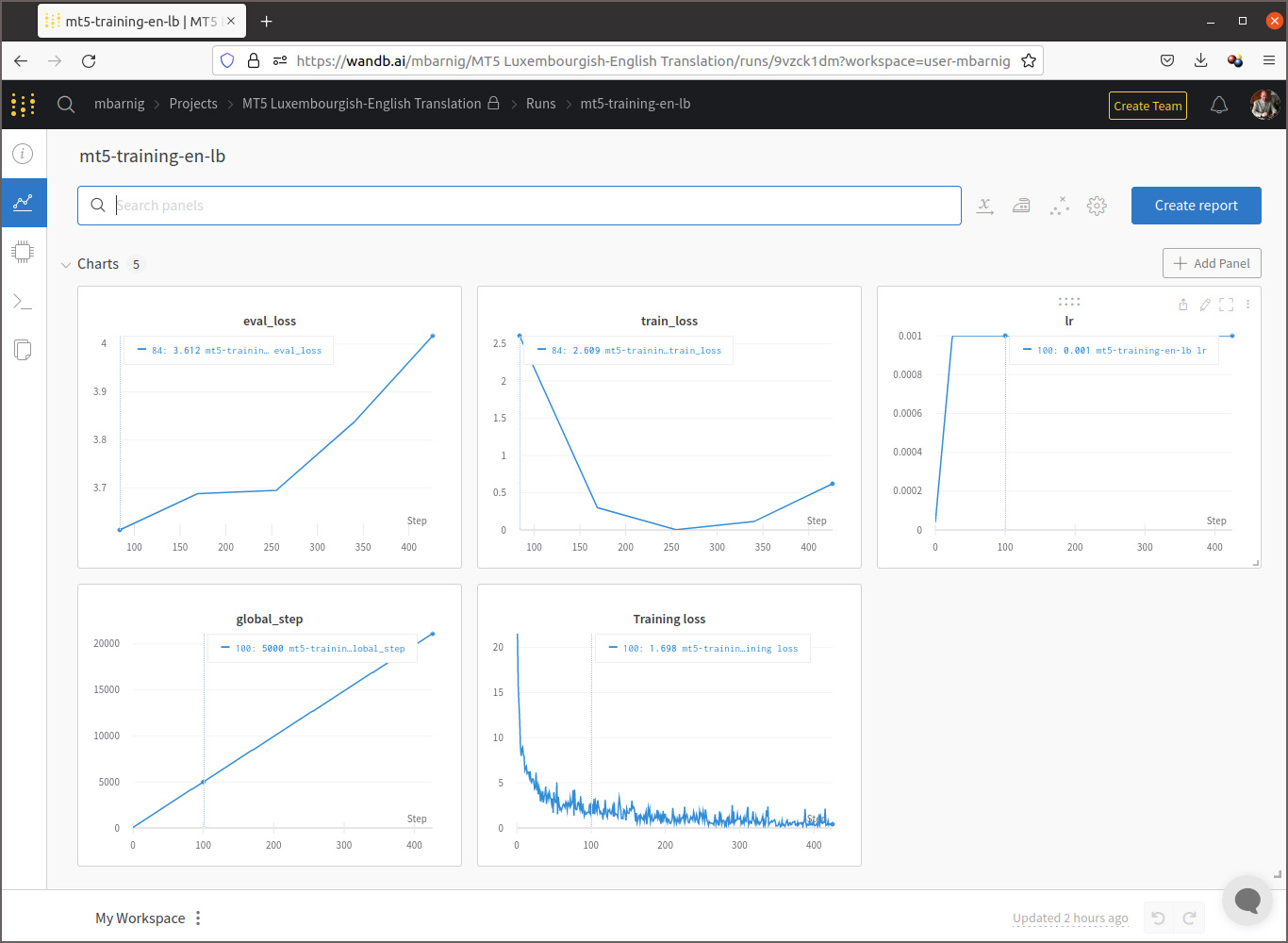
On constate que le coefficient de perte train est au début en baisse pour ensuite inverser sa pente, tandis que le coefficient de perte eval augmente continuellement, ce qui signifie qu’il y a un overfitting du modèle du fait que la taille du fichier d’entraînement est trop petit. Cela se confirme si on examine les résultats de la traduction dans mon espace de démonstration sur Huggingface. J’ai programmé une application commune pour comparer les résultats de la traduction anglais-luxembourgeois et vice-versa avec les trois modèles NLLB, MarianNMT et T5/mt5.
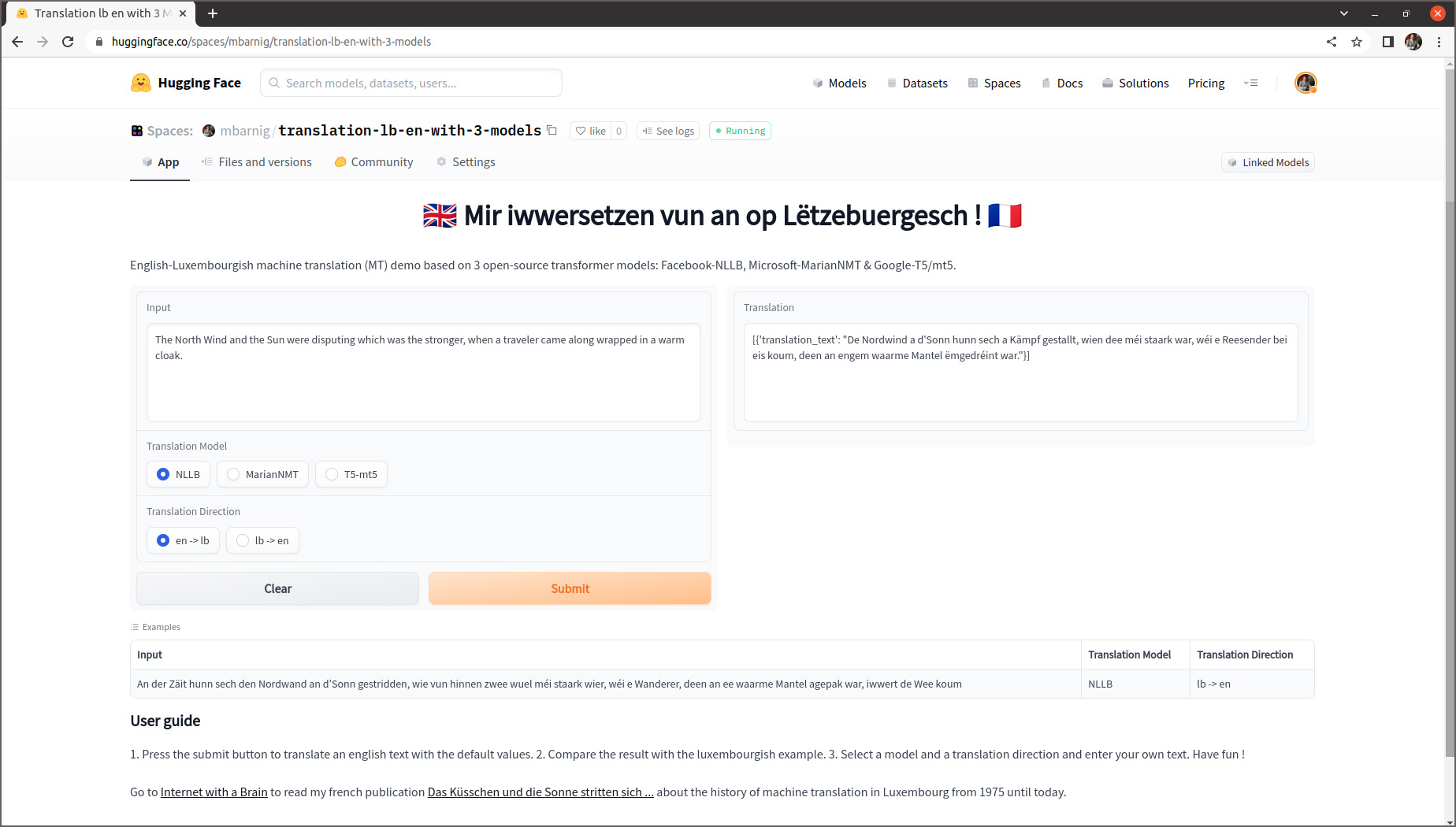
En entrant les mêmes textes dans l’application Goggle Translate, on se rend compte de la performance supérieure de ce modèle dont le code est fermé et propriétaire.
Métriques
Dans les chapitres précédents nous avons procédé à une évaluation subjective de la qualité de traduction des différents modèles basés sur l’intelligence artificielle. Il existe toutefois de nombreuses métriques pour procéder à une évaluation objective. Quelques exemples sont relevés ci-après :
- BLEU (Bilingual Evaluation Understudy)
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
- METEOR (Metric for Evaluation of Translation with Explicit Ordering)
- NIST (National Institute of Standards and Technology)
- LEPOR ((Length Penalty, Precision, n-gram Position difference Penalty and Recall)
- chrf++ (Character n-gram F-score)
Pour exprimer la qualité d’une traduction automatique, on mesure la différence entre la traduction machine et une, ou plusieurs, traductions de référence créées par l’humain pour une même phrase source. Il faut donc disposer d’un corpus de phrases pour la langue source et pour la langue cible. Facebook a publié récemment sur Github un corpus public de référence appelé Flores-200. Il se compose d’un fichier csv pour chacune des 200 langues supportées par le modèle NLLB. Chaque fichier inclut 998 phrases présentées dans le même ordre, ce qui permet d’automatiser aisément l’évaluation d’un nouveau modèle de traduction machine pour un couple de langues déterminées. Les trois premières phrases en anglais et en luxembourgeois du corpus Flores-200 sont affichées ci-après à titre d’exemple.
| On Monday, scientists from the Stanford University School of Medicine announced the invention of a new diagnostic tool that can sort cells by type: a tiny printable chip that can be manufactured using standard inkjet printers for possibly about one U.S. cent each. |
| Lead researchers say this may bring early detection of cancer, tuberculosis, HIV and malaria to patients in low-income countries, where the survival rates for illnesses such as breast cancer can be half those of richer countries. |
| The JAS 39C Gripen crashed onto a runway at around 9:30 am local time (0230 UTC) and exploded, closing the airport to commercial flights. |
| …………….. |
| E Méindeg hu Wëssenschaftler vun der Stanford University School of Medicine d’Erfindung vun engem neien Diagnosgeschier ugekënnegt, dat Zellen no Typ sortéiere kann: e klengen dréckbaren Chip, dee mat Hëllef vun engem Standardtëntestraldrécker fir méiglecherweis ongeféier een US-Cent d’Stéck hiergestallt ka ginn. |
| Féierend Fuerscher soen, datt dëst d’Fréierkennung vu Kriibs, Tuberkulos, HIV a Malaria bei Patienten a Länner mat nidderegem Akommes brénge kéint, wou d’Iwwerliewenstauxe bei Krankheeten ewéi Broschtkriibs hallef esou héich kënne sinn ewéi a méi räiche Länner. |
| D’JAS 39C Gripen ass géint 9.30 Auer Lokalzäit (0230 UTC) op eng Rullbunn gestierzt an explodéiert, wouduerch de Flughafe fir kommerziell Flich gespaart gouf. |
| …………….. |
Après la comparaison des résultats, un score est attribué pour chaque phrase traduite. Puis une moyenne est calculée sur l’ensemble du corpus afin d’estimer la qualité globale du texte traduit. Parmi la multitude des métriques d’évaluation MT, BLEU constitue la métrique la plus populaire et la moins coûteuse. Elle a été développée en 2002 par Kishore Papineni pour IBM. La formule mathématique pour générer les scores se base sur des unigrammes, bigrammes, trigrammes et quadrigammes (n-grammes), mais je vais vous épargner les explications afférentes qui dépassent le cadre de la présente description. Je me limite à présenter quelques résultats représentatifs extraits des métriques pour la traduction automatique des 200 x 200 couples de langues supportés par les modèles NLLB. Les scores afférents sont exprimés avec la métrique chrf++ qui fournit des évaluations plus pertinentes que la métrique BLEU.
| Direction Traduction | Métrique chrf++ |
| en -> de | 62,8 |
| en -> fr | 69,7 |
| en -> lb | 56 |
| de -> en | 67,5 |
| de -> fr | 61,4 |
| de -> lb | 52 |
| fr -> en | 68,4 |
| fr -> de | 56,3 |
| fr -> lb | 49,6 |
| lb -> en | 69,6 |
| lb -> de | 60,1 |
| lb -> fr | 62,4 |
| lb -> zho | 12,9 |
| lb -> ja | 24,6 |
La meilleure qualité a été calculée pour la traduction luxembourgeois – anglais (chrf++ = 69,6), la plus basse pour la traduction luxembourgeois – chinois (chrf++ = 12,9).
Conclusions
J’utilise la traduction automatique depuis plus de 10 ans dans le cadre de mes projets de recherche dans le domaine de l’intelligence artificielle pour lire des informations publiées sur le web dans des langues exotiques, comme le coréen, le chinois, le russe etc. Même si la qualité de la traduction n’est pas parfaite, elle est suffisante pour comprendre l’essentiel du contenu. J’apprécie la traduction de documents étrangers en luxembourgeois sur Google Translate lors de la rédaction d’articles techniques en luxembourgeois que je partage, de temps en temps, sur les réseaux sociaux. Le support de la langue luxembourgeoise dans les modèles de traduction machine à source ouverte récents, en combinaison avec la mise à disposition d’outils de programmation libres sur les plate-formes Github et Huggingface, facilitera le fin réglage des modèles de traduction luxembourgeois pour des domaines spécifiques, par exemple pour la biologie, la médecine, les finances etc. Si on passe en revue l’histoire de la traduction automatique, on constate une évolution exponentielle. Il y a eu plus d’innovations et de changements au courant des deux dernières années que pendant la période de 50 ans (de 1970 à 2019) précédente.
Bibliographie
Livres
- Machine Translation, Michael Zarechnak
- Early years in machine translation,
- La traduction automatique, Anne-Marie Loffler-Laurian
- Scientific Babel, Michael D. Gordin, 2015
Magazines

Articles sur le web
- Le traducteur, une espèce en voie de disparition ?, Joss Morkens, 2022
- GPT-1, GPT-2 and GPT-3, 360DigiTMG Team, 2021
- Proceedings of the Machine Translation Conferences : 2016, 2017, 2018, 2019, 2020, 2021
- Data Distillation, Alex Dyakonov, 2020
- BLEU, un algorithme qui calcule la qualité des traductions machine, Loréna Abate, 2019
- Histoire de la traduction automatique, Kate Chernavina, 2018
- Lancement d’un atlas sonore des langues régionales en France, 2017
- Google Translate gëtt et elo och op Lëtzebuergesch, Luxemburger Wort, 2016
- La traduction au sein des institutions européennes, Thierry Fontenelle, 2016
- Le fantasme de la traduction automatique : esquisse d’un imaginaire frelaté, Geneviève Has, 2015
- La traduction à la Commission : 1958 – 2010, 2009
- Gachot veut rouvrir les vannes de la croissance, Les Echos, 1994
- The northwind and the sun in phonetics, Pr Jo Verhoeven
- Ein Schritt zur automatischen Übersetzung ins Deutsche: Grammatik zu Algorithmen formen, Computerwoche 1987
- Systran for Esprit and ECAT Bureau Service, Leonard Siebenaler, 1986
- Rapport CIDST 1975 – 1977, 1978
- Organisation de la CE, 1976
- Rapport CIDST pour 1972 et 1973, 1974