
Dernière mise à jour: 19 mars 2017
Chronologie Internet
Il y a presque 4 ans, j’avais publié sur mon blog une proposition de diviser la chronologie du web (timeline) en neuf époques. J’avais opté pour le nom de web intelligent (web 3.5) pour caractériser la période de début 2015 à mi 2017.
Pour moi, le web intelligent a les compétences suivantes:
- il parle notre langue
- il lit notre écriture
- il comprend notre langage et reconnaît notre voix
- il reconnaît notre visage et décode nos émotions
- il interprète des images et scènes vidéo
- il a des connaissances vastes sur tous les sujets
- il prend des décisions autonomes
- il est capable d’apprendre afin de parfaire ses compétences
Les technologies qui sont à la base de ces compétences existent depuis des années, voire des décennies. Ils ont fait l’objet de recherches, de tests, de prototypes, d’applications innovantes et de produits commerciaux, mais le plus souvent d’une façon isolée, pour une seule compétence.
Le GPS nous parle dans la voiture, Siri et Alexa répondent à nos questions sur le mobile, Google Photo et Facebook reconnaissent les visages sur nos photos, Wikipedia sait tout (ou presque), des outils d’aide à la décision sont omniprésents et les réseaux neuraux permettent aux machines d’apprendre en profondeur (deep learning).
Ce qui a changé en 2016, c’est le fait que toutes ces technologies ont été assemblées par Google et par Amazon Web Services (AWS) dans des produits commerciaux d’intelligence artificielle qui sont maintenant à la disposition des développeurs du monde entier.
Le web 3.5 est donc devenu réalité.
Google Cloud Platform
Google est bien connu pour son moteur de recherche, sa plateforme vidéo Youtube et ses services de traduction. Depuis 2011, Google offre aux programmeurs et sociétés d’héberger leurs propres applications sur la même infrastructure que celle qu’elle utilise en interne. Ce service est appelé Google Cloud Platform et se compose d’une famille de produits, chacun comportant une interface web, un outil de lignes de commande, et une interface de programmation applicative REST. Parmi ces produits on distingue:
- Google App Engine
- Google Storage
- Goggle Compute Engine
- Google Translate
L’ensemble des produits et services est décrit sur la page web cloud.google.com.
En mars 2016, Google a annoncé le lancement de la famille Cloud Machine Learning service mainstream. Les services suivants font partie, entre autres, de cette famille:
- Cloud ML : Large Scale Machine Learning Service
- Cloud Natural Language API : Powerful Text Analysis
- Cloud Speech API : Powerful Speech Recognition in 80 languages
- Cloud Translate API : Fast, Dynamic Translation
- Cloud Vision API : Powerful Image Analysis
Google Cloud Vision
De prime abord, je me suis intéressé pour le nouveau service Cloud Vision. Dans le passé j’avais déjà effectué des tests avec différentes applications de reconnaissance faciale et de lecture de textes. Les contributions afférentes sont disponibles sur mon blog.
Pour faire des tests, j’ai pris au hasard quelques photos de mes petits-enfants.
Les résultats de Google Vision sont affichés dans plusieurs onglets:
- Faces : reconnaissance de visages et d’émotions
- Labels : reconnaissance de scènes et d’objets
- Text : lecture de caractères et de textes
- Colors : classification des couleurs dominantes
- Safe Search : contenus avec nudité, violence, haine ou sujets médicaux
- JSON Response : ensemble détaillé des données en format JSON
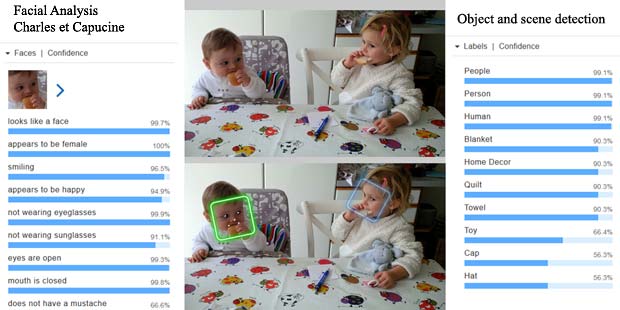
Les résultats ont été assemblés dans une seule image, par copie-collage, pour donner une meilleure vue globale.
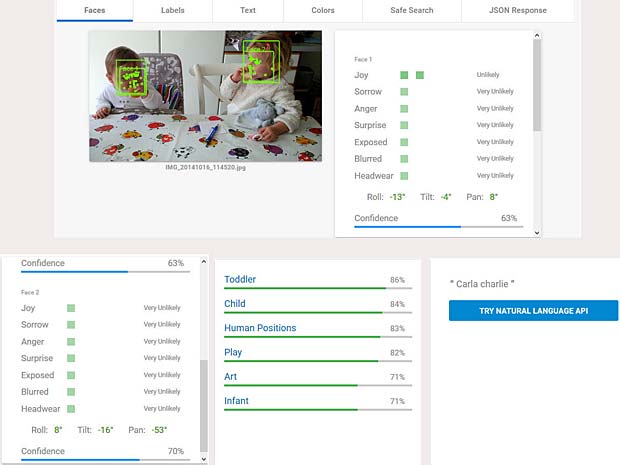 Google Vision ne fournit pas un service de reconnaissance des personnes comme dans Google Photo, mais se limite à détecter les visages et à interpréter les émotions. Dans la figure ci-dessus les informations pour les deux visages sont indiquées en haut à droite (Charles) et en bas à gauche (Capucine). Les étiquettes (label) pour la scène sont affichées en bas au milieu, le texte reconnu se trouve en bas à droite.
Google Vision ne fournit pas un service de reconnaissance des personnes comme dans Google Photo, mais se limite à détecter les visages et à interpréter les émotions. Dans la figure ci-dessus les informations pour les deux visages sont indiquées en haut à droite (Charles) et en bas à gauche (Capucine). Les étiquettes (label) pour la scène sont affichées en bas au milieu, le texte reconnu se trouve en bas à droite.
Les termes reconnus “Carla” et “Charlie” sont les noms de vaches qui figurent sur la nappe de la table, comme on peut le voir sur l’agrandissement ci-dessous.

Un exemple de l’onglet “JSON Response” est présenté ci-après. Tous les détails de l’analyse sont fournis dans cette structure JSON.
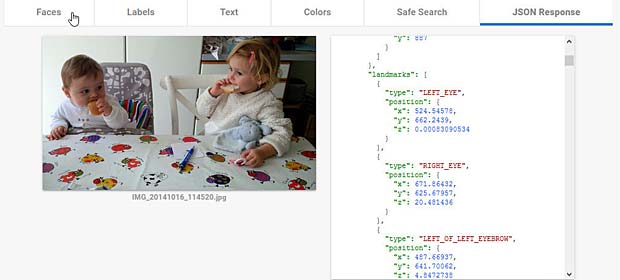
En ce qui concerne l’analyse proprement dite, Google Vision ne détecte pas d’émotions sur les visages des deux enfants, sauf une légère surprise sur le visage de Charles. Hormis la reconnaissance de personnes (toddler, child), Il n’y a guère d’informations sur le contexte.
Pour les images suivantes, seuls les résultats “Faces” et “Labels” sont présentés dans les figures montées.
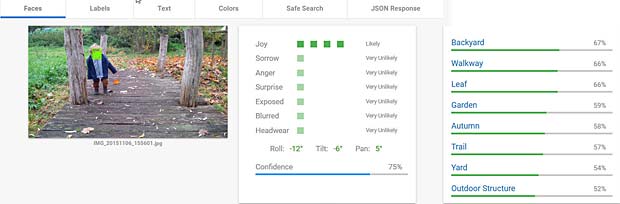 Google Vision voit de la joie dans le visage de Charles qui se trouve dehors, dans une sorte de jardin, avec des feuilles, en automne. Bonne interprétation.
Google Vision voit de la joie dans le visage de Charles qui se trouve dehors, dans une sorte de jardin, avec des feuilles, en automne. Bonne interprétation.
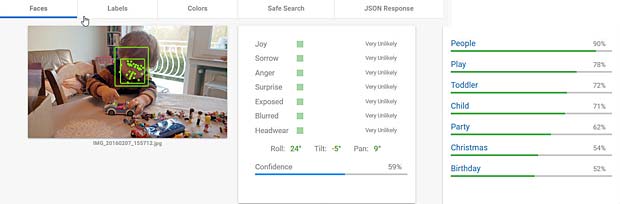 Google Vision estime que Charles fête son anniversaire à Noël. En réalité il joue en février 2016 avec du Lego. Echec.
Google Vision estime que Charles fête son anniversaire à Noël. En réalité il joue en février 2016 avec du Lego. Echec.
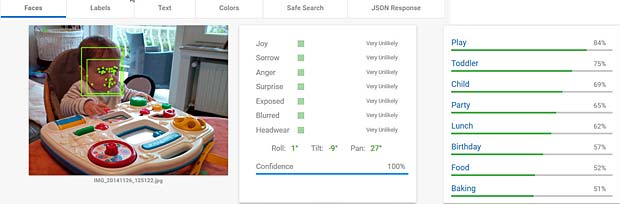 L’activity-Center Fisher-Prize de Thomas fait penser Google Vision à un anniversaire et à de la nourriture.
L’activity-Center Fisher-Prize de Thomas fait penser Google Vision à un anniversaire et à de la nourriture.
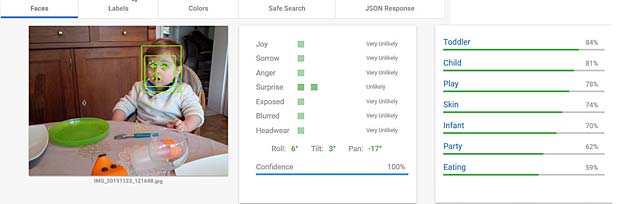
Google Vision considère que Thomas est un peu surpris et combine les activités jouer et manger. Bien.
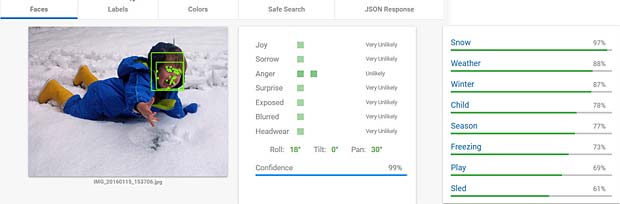
Thomas semble être en colère et se trouve dans la neige, en hiver et il a froid. Analyse correcte.
Amazon Web Services
Tout le monde connaît Amazon en tant que fournisseur en ligne de livres et d’autres objets non périssables, mais peu de personnes savent que Amazon est un des plus grand fournisseurs mondiaux de services informatiques sous le nom de Amazon Web Services (AWS). Tout comme Google, Amazon profite de l’infrastructure nécessaire pour ses propres besoins pour offrir de la capacité et des services à des tiers. Lancé en 2006, AWS se classe aujourd’hui au premier rang des fournisseurs Cloud avec une part de marché de 31%, devant Microsoft (11%) et IBM (7%).
J’utilise les services d’AWS depuis octobre 2008.
Le 30 novembre 2016, Werner Vogels, le CTO (Chief Technological Officer) de Amazon, annonçait sur son blog All Things Distributed le lancement des nouveaux services d’intelligence artificielle (AmazonAI) de AWS.
Amazon AI
Le but d’Amazon AI est d’apporter une intelligence artificielle puissante à tous les développeurs. La gamme des services Amazon AI se compose de:
- Amazon Lex : concevoir des interfaces conversationnelles ayant recours à la voix et au texte, via les mêmes technologies d’apprentissage approfondi que celles utilisées par Alexa
- Amazon Rekognition : reconnaissance d’image basée sur l’apprentissage approfondi
- Amazon Polly : convertir un texte en voix numérique
- Amazon Machine Learning : un service d’apprentissage automatique évolutif pour les développeurs
Chez Amazon AI, je me suis également intéressé d’abord pour Amazon Rekognition. Du premier coup j’ai vu des ressemblances avec la technologie Orbeus ReKognition que j’avais exploré en 2014. Dans la suite j’ai trouvé sur le net un article de Bloomberg relatant que Amazon a acquis en automne 2015 la startup Orbeus Inc., mais sans en faire une annonce officielle.
Amazon Rekognition ne fournit pas seulement des informations sur les émotions détectées sur les visages, mais également des renseignements sur le sexe et sur des accessoires comme lunettes, barbes, moustaches. Dans la détection des scènes et objets on reçoit en général plus d’étiquettes qu’avec Google Vision. Amazon Rekognition n’offre toutefois pas une reconnaissance intégrée de textes.
Les résultats des tests effectués avec les mêmes six photos de mes petits-enfants sont présentés ci-après. On peut donc les comparer avec ceux fournis par Google Vision.
Charles est identifié comme une fille, ce qui n’est pas correct. Le décor est reconnu correctement comme maison et même le Dudu de Capucine est associé correctement à une courtepointe (quilt, towel).

La scène est considérée comme un labyrinthe, une arène ou un amphithéâtre. Il n’y a pas de notion de nature ou de bois. Google a fait mieux. Amazon AI est toutefois d’accord avec Google Vision que Charles sourit.
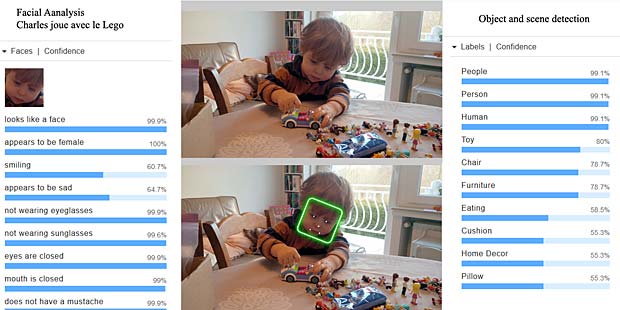
Le système reconnaît des personnes, des jouets, une chaise et un coussin dans un décor de maison. Il confond toutefois des jouets avec de la nourriture. Google Vision n’a pas fait mieux.
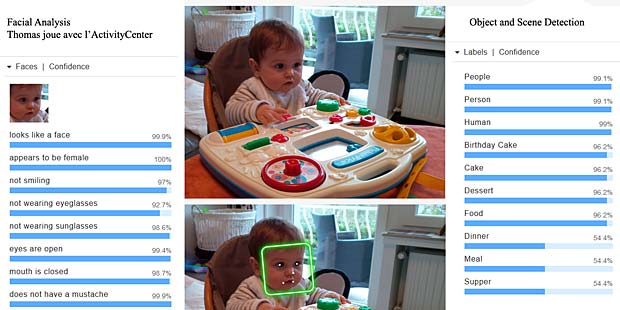
Le centre d’activités Fisher-Price de Thomas est identifié comme un gâteau d’anniversaire, ou un dessert, en tout cas quelque chose pour manger. Google Vision a fait les mêmes réflexions.
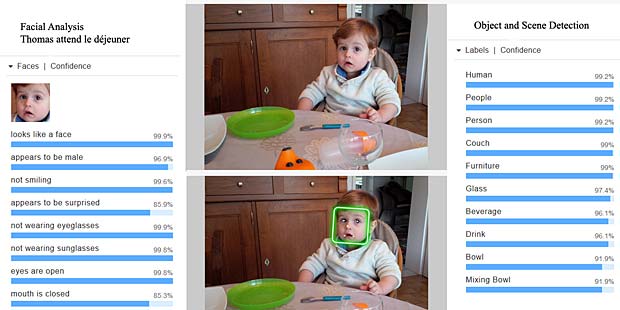
Dans cette scène, le système détecte correctement qu’il s’agit d’objets pour boire et manger. Thomas, plus âgé que sur la précédente photo, est reconnu maintenant comme un garçon qui ne rit pas, mais qui paraît surpris.
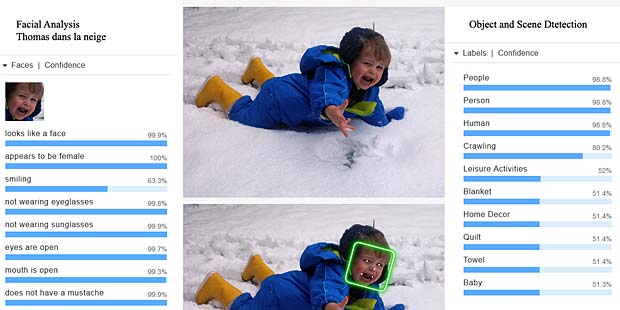
La scène n’est pas reconnue comme activité dans la neige et le système interprète le pleur de Thomas comme un grand sourire. Echec complet.
Amazon Face Comparison
Le service Amazon Rekognition comprend l’application Face Comparison (comparaison faciale) qui est très performante. A partir d’une photo avec un visage de référence, le service Face Comparison fournit des taux de ressemblance des visages qui figurent sur une photo de comparaison. La série des figures ci-dessous montre quelques exemples:

Thomas est reconnu avec une fiabilité de 93%; similitude avec Charles (83%) et Capucine (76%).

Charles n’est pas reconnu, mais il y a similitude de 74,9% avec Thomas et de 55,1% avec Capucine.

Capucine est reconnue avec une fiabilité de 91%. Il n’y a pas de ressemblance avec les autres.

Marco est reconnu avec une fiabilité de 92%. Il n’y a pas de similitude détectée avec les enfants.

Astor, qui ne figure pas sur la photo à droite, ne ressemble à personne sur cette photo
Amazon fournit également un service de reconnaissance faciale. Il s’agit d’un processus d’identification et de vérification de l’identité d’une personne, en recherchant son visage dans un répertoire d’images de visages. Un répertoire d’images de visages est un index de recherche de vecteurs de caractéristiques faciales. AWS offre plusieurs interfaces (API) pour gérer un tel répertoire et pour ajouter ou supprimer des visages de référence dans le répertoire.
En ce temps Google Vision ne supporte pas encore la reconnaissance des visages dans son API public. Il n’y a donc pas moyen de comparer les performances avec Amazon Rekognition.
Dessins de Capucine
Pour pousser Google Vision et Amazon Rekognition aux limites, j’ai soumis deux dessins récents de ma petite-fille Capucine (4 ans et demi) et une des premières ébauches d’écriture de son nom aux deux systèmes.

Dessins et texte de Capucine à l’âge de 4 ans et demi
Les résultats fournis par Google Vision et Amazon Rekognition ont été assemblés chaque fois dans une seule image.
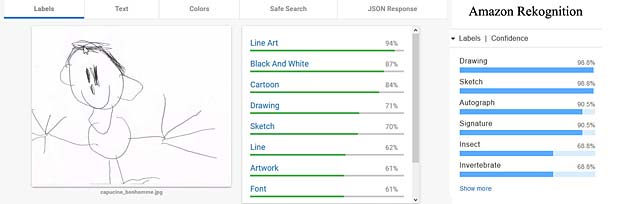 Le dessin du bonhomme est reconnu par Google Vision (résultats au milieu) comme cartoon et oeuvre d’art, tandis que Amazon Rekognition voit une signature ou un insecte. Aucun des deux systèmes reconnaît une figure humaine.
Le dessin du bonhomme est reconnu par Google Vision (résultats au milieu) comme cartoon et oeuvre d’art, tandis que Amazon Rekognition voit une signature ou un insecte. Aucun des deux systèmes reconnaît une figure humaine.
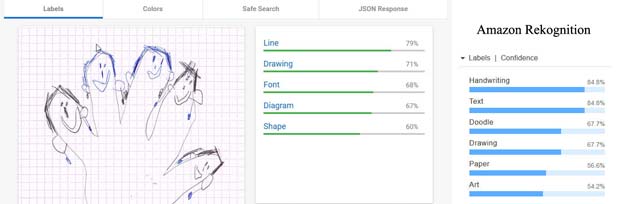 Les visages avec des boucles d’oreille qui ornent le contour de la main de Capucine ne sont pas identifiés comme tels par aucun des systèmes. Ce sont des lignes, des dessins, des formes ou diagrammes. Amazon Rekognition est au moins d’avis qu’il s’agit de l’art.
Les visages avec des boucles d’oreille qui ornent le contour de la main de Capucine ne sont pas identifiés comme tels par aucun des systèmes. Ce sont des lignes, des dessins, des formes ou diagrammes. Amazon Rekognition est au moins d’avis qu’il s’agit de l’art.
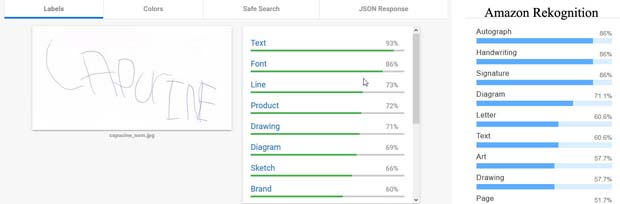 En ce qui concerne le nom de Capucine, Google Vision estime qu’il s’agit d’un texte, mais n’est pas en mesure de le lire. L’OCR (optical character recognition) ne fait pas encore partie du produit Amazon Rekognition. Ce système détecte toutefois qu’il s’agit de textes, de caractères, d’une signature ou d’un autographe.
En ce qui concerne le nom de Capucine, Google Vision estime qu’il s’agit d’un texte, mais n’est pas en mesure de le lire. L’OCR (optical character recognition) ne fait pas encore partie du produit Amazon Rekognition. Ce système détecte toutefois qu’il s’agit de textes, de caractères, d’une signature ou d’un autographe.
Conclusions
Les performances des deux systèmes Google Vision et Amazon Rekognition sont impressionnantes. Globalement Google Vision semble être plus fiable dans ses analyses en comparaison avec Amazon Rekognition, abstraction faite de la reconnaissance faciale d’Amazon qui est unique.
Bien sûr il y a encore un besoin d’amélioration pour les deux systèmes. Les services Machine Learning des deux fournisseurs permettent de mieux adapter la reconnaissance d’objets et de scènes à son propre environnement, en formant les systèmes moyennant un échantillon d’images et de photos d’apprentissage, avec des étiquettes (labels) sélectionnées manuellement et des étiquettes corrigées en cas d’erreur.
Google profite d’ailleurs sur son site de démonstration d’une variante de son système reCAPTCHA pour exclure les robots à l’utilisation de sa plateforme Cloud. Les réponses fournies par les humains sont utilisées pour parfaire Google Vision.
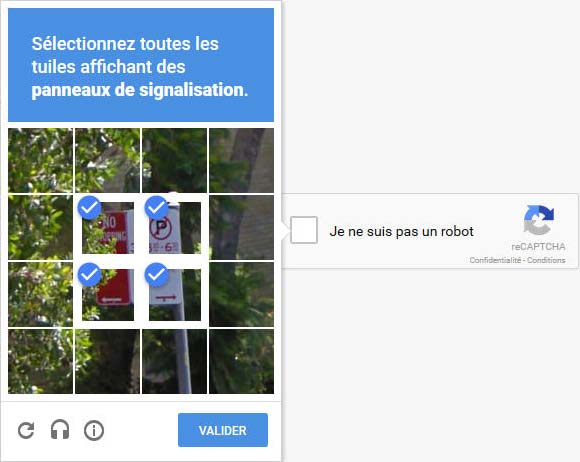
Google CAPTCHA: Completely Automated Public Turing test to tell Computers and Humans Apart