
Dernière mise à jour : 1er août 2022
Introduction
Dans l’attente de l’élimination de quelques bogues dans les modèles de synthèse vocale (TTS) par la communauté Coqui.ai, aux fins de progresser avec mon projet de création d’une voix TTS luxembourgeoise, je me suis focalisé les dernières semaines sur la reconnaissance automatique de la parole luxembourgeoise (STT: Text to Speech ou ASR: Automatic Speech Recognition).
Mes premiers essais effectués dans ce domaine en janvier 2022 étaient encourageants. Impressionné par la présentation du premier modèle STT luxembourgeois par le Pr Peter Gilles de l’université du Luxembourg sur la plateforme d’intelligence artificielle HuggingFace en février 2022, j’ai poursuivi mes tests avec le projet Coqui-STT (version 1.3.0).
Bases de données LB-2880 et LB-27072
Pour entraîner un modèle STT avec des réseaux neuronaux, il faut disposer d’une base de données audio avec les transcriptions de la parole enregistrée. Au début 2022 j’avais finalisé une base de données avec les enregistrements de quatre oratrices (au total 1005 échantillons) pour l’entraînement d’un modèle TTS luxembourgeois avec quatre voix. Entretemps j’ai complété cette base avec des enregistrements publics de trois orateurs (1.676 échantillons) et je l’ai étoffé avec les enregistrements audio du dictionnaire luxembourgeois LOD (24.678 échantillons).
Ainsi j’ai pu constituer deux ensembles de données avec 2.880, respectivement 27.072, échantillons qui se prêtent pour l’entraînement de modèles TTS et STT. Je vais prochainement publier ces bases de données LB-2880 et LB-27072 sur mon compte Github.
Les deux ensembles sont segmentés en trois volets. Le plus large (train.csv) est utilisé pour l’entraînement du modèle, le deuxième (val.csv) sert à mesurer le progrès de l’entraînement après chaque cycle d’itérations (époque) et le troisième (test.csv) permet de tester la performance du modèle à la fin de l’entraînement. Les détails sont indiqués dans le tableau qui suit:
| Base de données | LB-2880 | LB-27072 |
| Durée totale | ca 7 heures | ca 13 heures |
| échantillons train | 2560 | 25600 |
| échantillons val | 192 | 1344 |
| échantillons test | 128 | 128 |
Transfert d’apprentissage
Convaincu que le seul moyen pour réussir l’entraînement d’un modèle STT luxembourgeois consiste à se baser sur un large modèle pré-entraîné dans une autre langue, je me suis tout de suite concentré sur cette option de transfert d’apprentissage. Les résultats impressionnants que le Pr Peter Gilles a obtenu sur base du modèle wav2vec2-XLS-R-300m créé par Meta AI (Facebook) ont renforcé ma conviction.
Coqui.ai a mis un modèle pré-entraîné en langue anglaise à disposition de la communauté. Comme la langue luxembourgeoise utilise un alphabet plus large que l’Anglais avec les caractères accentués suivants
['à','á','â','ä','ç','è','é','ê','ë','î','ï','ô','ö','û','ü']il faut supprimer la dernière couche de neurones du modèle pré-entraîné anglais pour pourvoir l’entraîner avec une base de données luxembourgeoise. Le hyper-paramètre de configuration ‘--drop_source_layers 1‘ permet de remplacer la dernière couche avec une nouvelle couche, initialisée avec l’alphabet luxembourgeois.
Hélas les premiers résultats ne répondaient pas du tout à mes attentes et les métriques affichées étaient plus mauvaises que celles obtenues lors de mes premiers tests, effectués à partir de zéro au début de l’année.
Modèles HuggingFace
Pour exclure que la qualité de ma base de données soit insuffisante, j’ai essayé de reproduire l’entraînement du premier modèle STT luxembourgeois sur HuggingFace avec mes propres données. Comme l’utilisation du modèle géant wav2vec2-XLS-R-300m, qui a servi de base pour le premier modèle, dépassait avec 300 millions de paramètres la capacité de traitement de mon ordinateur desktop, ainsi que celle de mon compte Pro sur la plateforme Google Colab, j’ai choisi un modèle pré-entraîné plus simple sur HuggingFace, à savoir le modèle Wav2Vec2-XLSR-53.
Avec un résultat WER de 0,17 j’ai réussi à obtenir des valeurs de même niveau que celles rapportées par le Pr Peter Gilles. Je vais prochainement publier mon modèle résultant sur mon compte HuggingFace.
Modèle Coqui-STT
On peut se demander quel est l’intérêt de s’acharner sur d’autres modèles STT que ceux offerts en source ouverte sur la plateforme formidable HuggingFace qui constitue aujourd’hui la référence en matière de l’apprentissage automatique profond et la plus grande communauté d’intelligence artificielle (AI) sur le web.
La réponse n’est pas simple. Une raison est certainement la taille des modèles STT entraînés. Si la taille est de quelques Giga Bytes dans le premier cas, elle est de quelques dizaines de Mega Bytes dans le cas du modèle Coqui-STT, ce qui permet de le porter sur un mobilophone (iOS et Android) ou sur un nano-ordinateur mono-carte comme le Raspberry Pi. Une deuxième raison est l’adaptation plus simple à son propre environnement. La configuration fine du modèle Coqui-STT simplifie son optimisation pour une utilisation spécifique. Personnellement je suis d’avis que la majeure raison constitue toutefois la transparence des processus. Les recettes HuggingFace sont une sorte de boîte noire d’usine à gaz qui fournit des résultats spectaculaires, mais dont le fonctionnement interne est difficile à comprendre, malgré l’ouverture du code. Pour apprendre le fonctionnement interne de réseaux de neurones un modèle comme Coqui-STT est plus approprié. J’ai donc continué à explorer l’apprentissage automatique profond du modèle Coqui-STT à partir de zéro, avec la certitude que ma base de données est de qualité.
Comme le fichier de configuration Coqui-STT comporte 96 hyper-paramètres, j’ai essayé de comprendre le rôle de chaque hyper-paramètre. J’ai vérifié également l’influence de quelques hyper-paramètres clés sur l’entraînement du modèle à l’aide d’une base de données restreinte de 100 échantillons. Les résultats significatifs sont commentés ci-après:
Similarité des entraînements
La taille d’un réseau de neurones est déterminée par le nombre de couches, le nombre de neurones par couche et le nombre de connexions entre neurones. Le total constitue le nombre de paramètres du modèle, à ne pas confondre avec les hyper-paramètres qui spécifient la configuration du modèle. Les paramètres du modèle sont initialisés au hasard au début de l’entraînement. Pour cette raison chaque processus d’entraînement produit des résultats différents. Le graphique qui suit montre en trois différentes vues que les différences sont négligeables.
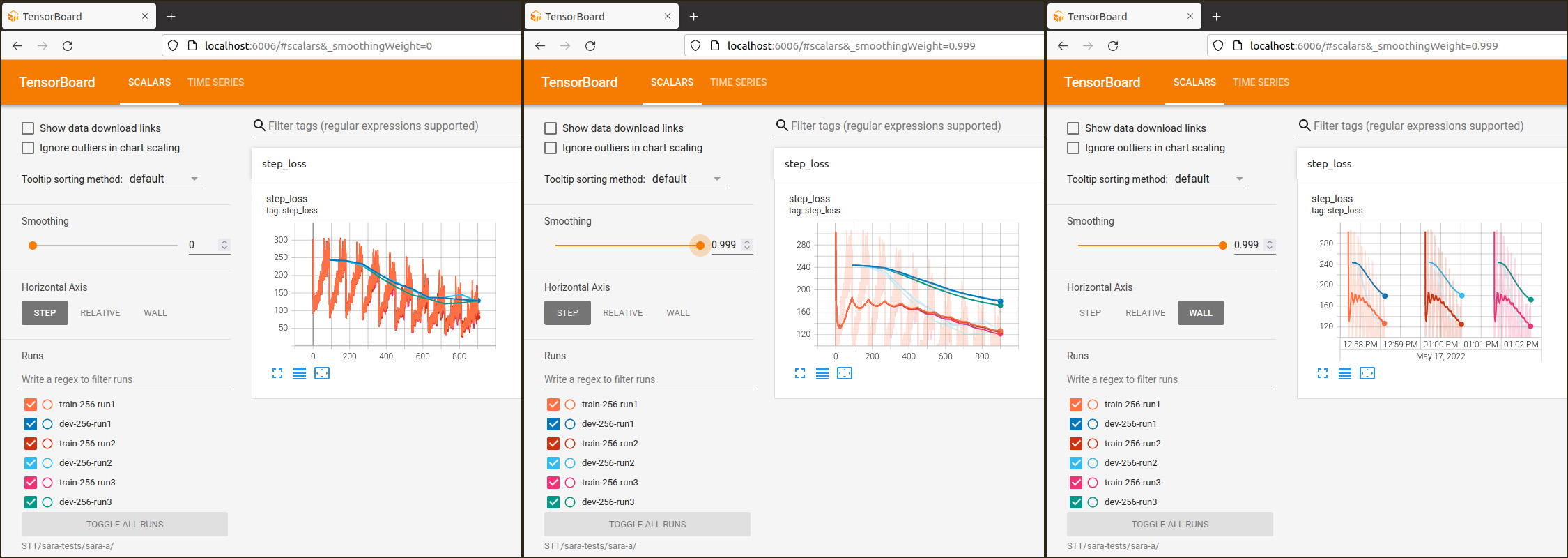
Nombre de couches
Le nombre de couches par défaut du modèle Coqui-STT est de 2048. Ce nombre est trop élevé pour une petite base de données. La figure suivante montre en deux vues l’évolution de l’entraînement en fonction du nombre de couches.
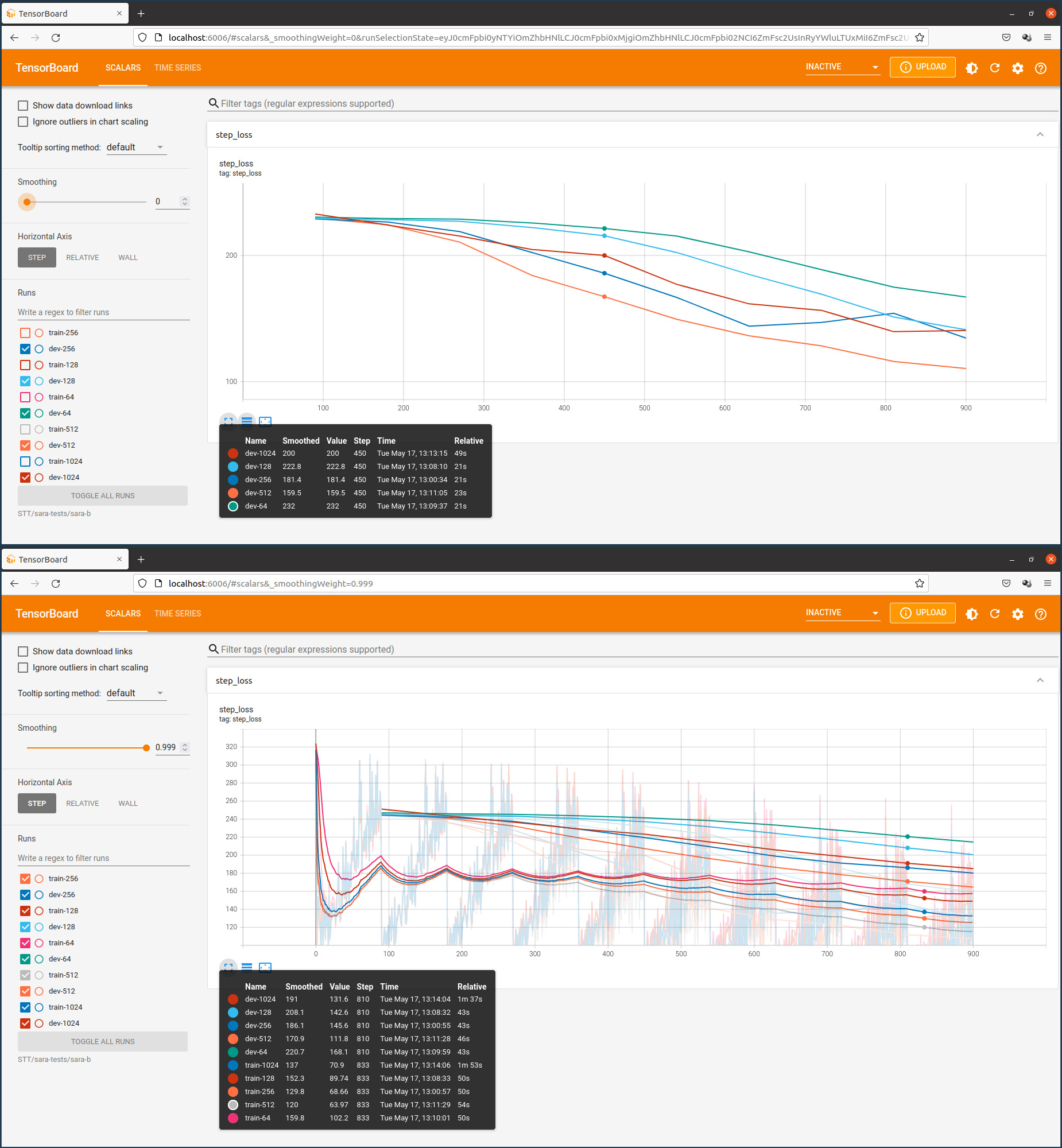
Nombre de lots
Les échantillons de la base de données pour entraîner le modèle STT sont répertoriés dans un fichier csv dans le format suivant:
wav_filename,wav_filesize,transcript
wavs/guy/walresultat-04.wav,232854,awer och net op eng spektakulär manéier obwuel a prozenter ausgedréckt ass de minus dach méi staark wéi a sëtz ausgedréckt
wavs/sara/Braun_042.wav,113942,ech hunn am bësch eng heemeleg kaz fonnt
wavs/jemp/WD-2007-jemp-07.wav,197962,wou en dag fir dag e puer vun deene fäll klasséiert
wavs/judith/marylux_lb-wiki-0138.wav,132754,florange ass eng franséisch uertschaft a gemeng am departement moselle a loutrengen
........... Chaque ligne du fichier csv correspond à un échantillon et comporte le chemin et le nom d’un fichier audio, la taille de ce fichier et la transcription de l’enregistrement audio, en lettres minuscules et sans signes de ponctuation. Les échantillons sont regroupés par lots lors de l’entraînement. Une itération d’entraînement comprend le traitement d’un seul lot. Une époque comprend le total des itérations pour traiter tous les échantillons. Si la taille d’un lot est égal à un, le nombre des itérations est égal au nombre des échantillons. Dans le cas d’un lot de 10, le nombre des itérations est seulement un dixième du nombre des échantillons. Comme le temps de calcul d’une itération n’augmente presque pas avec l’accroissement de la taille d’un lot, le temps d’entraînement se réduit de la même manière. On a donc intérêt à spécifier une taille élevée des lots. Hélas, la taille des lots est fonction de la mémoire disponible du processeur graphique (GPU). Une taille trop élevée génère des erreurs “memory overflow” .
J’ai réalisé tous mes entraînements sur mon ordinateur desktop avec GPU NVIDIA RTX2070 avec des lots de 32, respectivement de 16 dans certains cas spécifiques.
Rapport entre entraînement et validation
Le graphique qui suit montre l’évolution de l’entraînement pour une base de données déterminée en fonction de la répartition des échantillons pour l’entraînement et pour la validation.
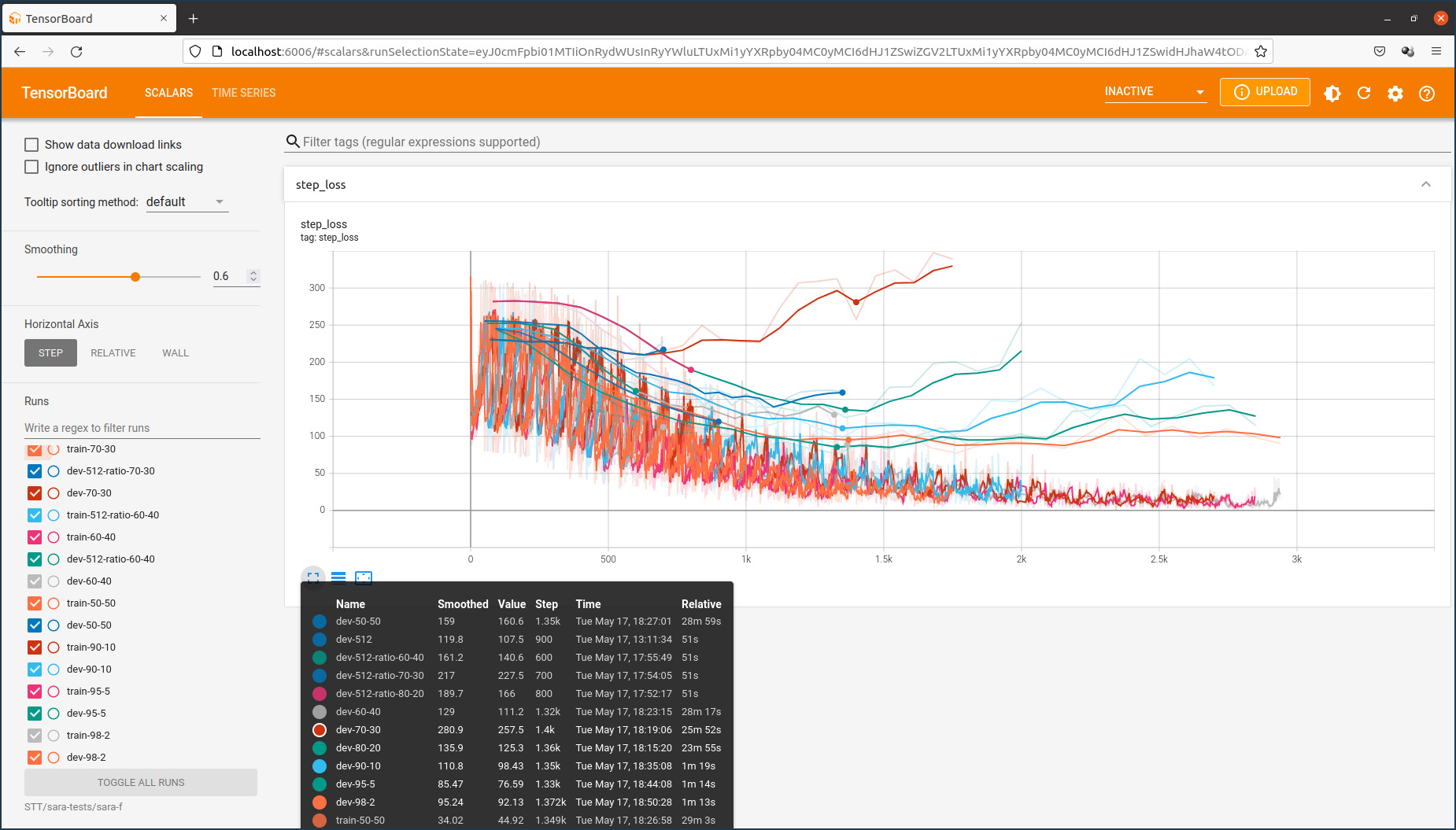
La segmentation de 93:7 que j’ai chois semble être appropriée.
Taux Dropout
Le mécanisme de “dropout” permet de réguler l’apprentissage d’un réseau de neurones et de réduire le “overfitting“. Il consiste à la suppression au hasard de connexions entre neurones pendant chaque itération à un taux spécifié dans la configuration. Le graphique suivant montre l’influence de ce taux sur l’entraînement. La valeur par défaut est de 0.05 et produit les meilleurs résultats.
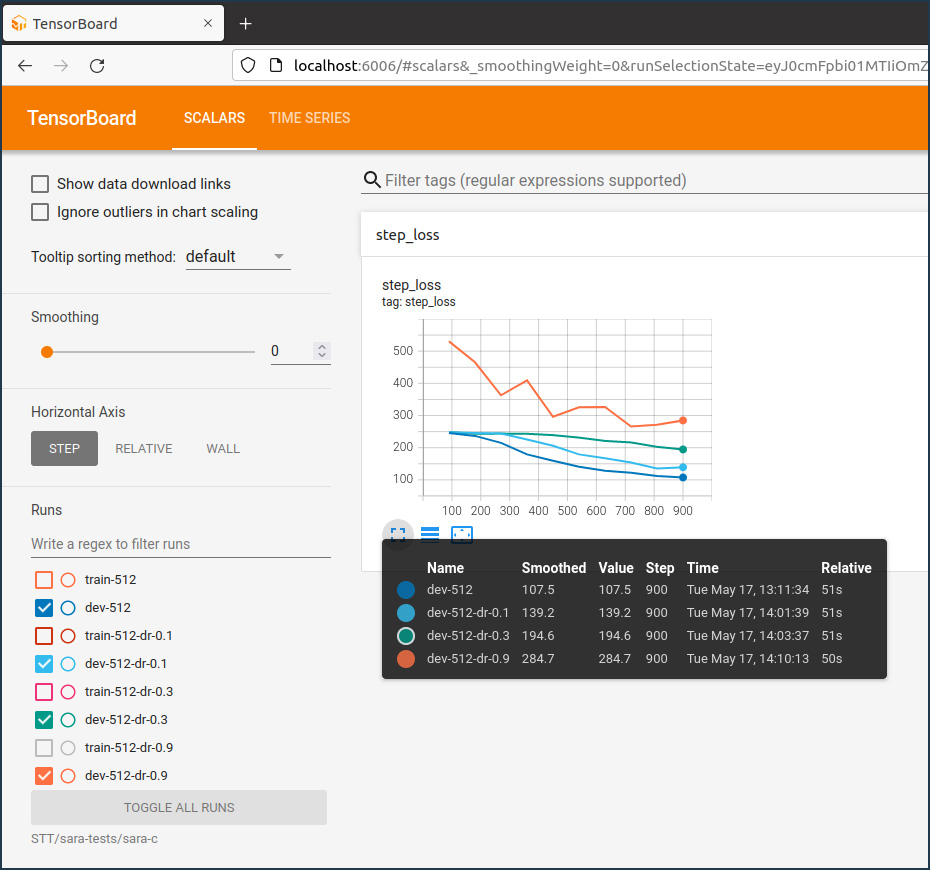
Taux d’apprentissage
Le taux d’apprentissage (learning rate) est un hyper-paramètre important dans la configuration d’un modèle STT ou TTS. La valeur par défaut du modèle Coqui-STT est de 0.001. La figure qui suit montre l’influence de ce taux sur l’entraînement.
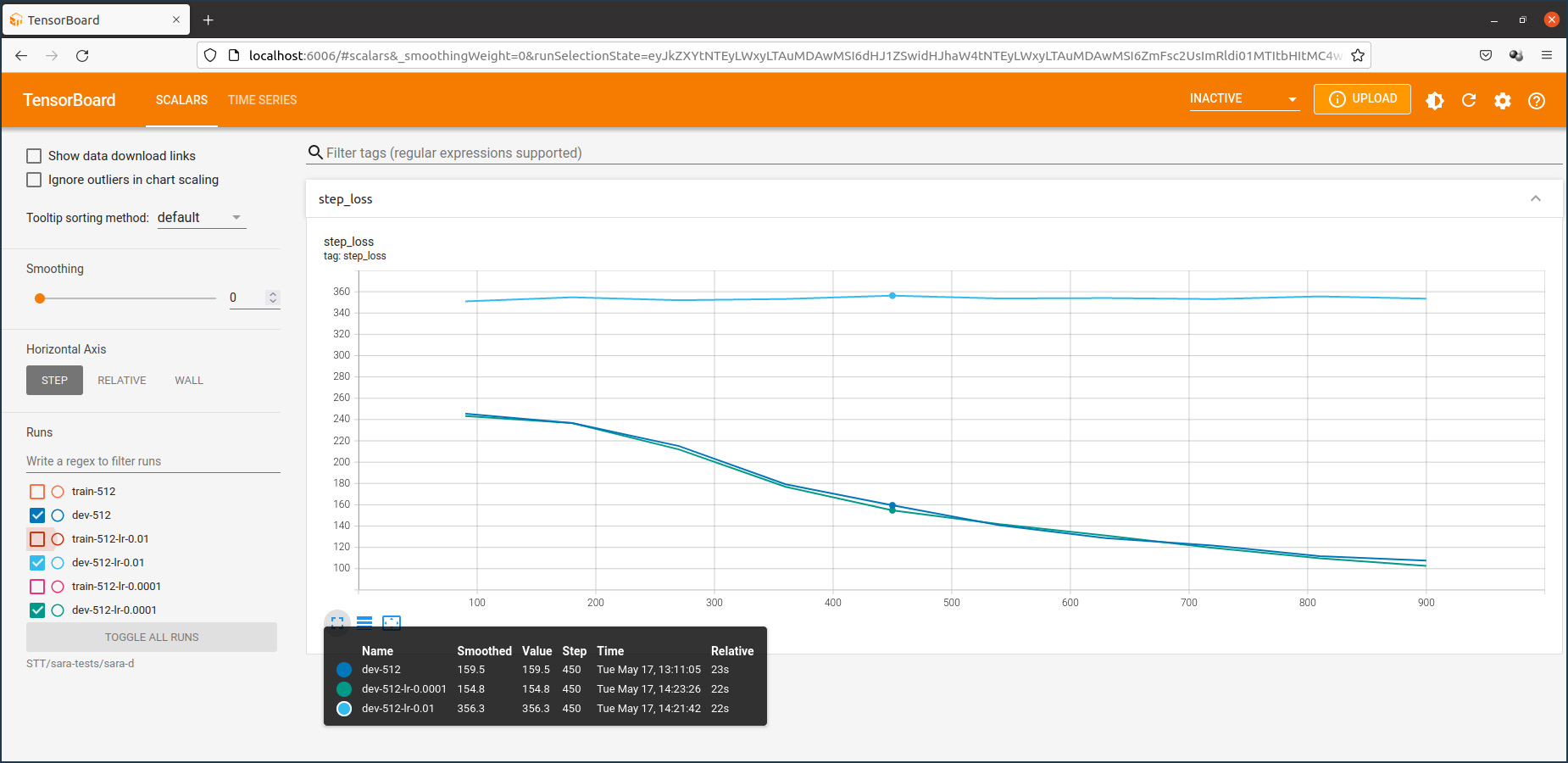
Une option de configuration intéressante proposée par le modèle Coqui-STT est la suite des hyperparamètres suivants:
--reduce_lr_on_plateau true
--plateau_epochs 3
--plateau_reduction 0.5Elle permet de modifier le taux d’apprentissage si la performance de l’entraînement ne progresse plus pendant trois époques. On parle de plateau dans la métrique affichée. J’ai utilisé cette option dans tous mes entraînements.
Augmentation des données
En général les modèles d’apprentissage automatique en profondeur sont très gourmands en données. Que faire si on ne dispose pas d’un nombre important de données pour alimenter un modèle ? On augmente les données existantes en ajoutant des copies modifiées des échantillons ! Dans le cas du modèle Coqui-STT on créé par exemple des fichiers audio modifiés avec les mêmes transcriptions. En changeant le volume, le ton, la cadence ou le spectre des enregistrements, on peut créer des échantillons supplémentaires.
L’outil data_augmentation_for_asr de Frederic S. Oliveira permet de générer aisément des nouveaux fichiers .wav et .cvs à ajouter à la base de données existante. J’ai réalisé des tests afférents en désignant ce processus comme augmentation externe. Le modèle Coqui-STT inclut une telle option sans recourir à un outil externe et sans augmenter le temps d’entraînement. L’hyper-paramètre suivant, ajouté au script d’entraînement,
--augment "pitch[p=1.0,pitch=1~0.2]" "tempo[p=1.0,factor=1~0.5]"permet par exemple de tripler le nombre des échantillons.
Suivant mes tests l’augmentation des donnés ne présente plus d’intérêt si le nombre des échantillons originaux dépasse quelques milliers.
Un type d’augmentation pour l’entraînement STT que je n’ai pas encore testé est la création d’échantillons synthétiques moyennant un modèle TTS luxembourgeois. C’est une piste que je vais encore explorer.
Résultats des entraînements avec les deux bases de données
LB-2880
La base de données LB-2880 comprend 2530 échantillons enregistrés par 4 oratrices et par 3 orateurs, ainsi que 350 mots du dictionnaire LOD. Le tableau qui suit relève les résultats pour des entraînements avec différents paramètres, pendant 30 époques chacun:
| couches | lot | augmentation | meilleur modèle acoustique | WER | CER | LOSS | |
| 1024 | 16 | sans | best_dev_1760 | 0.705 | 0.221 | 73,9 | |
| 1024 | 16 | interne | best_dev_2720 | 0,717 | 0.222 | 69,0 | |
| 2048 | 16 | sans | best_dev-1440 | 0.723 | 0.224 | 78.5 | |
| 2048 | 16 | externe | best_dev-2395 | 0.776 | 0.271 | 78.4 | |
| 2048 | 16 | interne | best_dev-3520 | 0.710 | 0.231 | 70,8 |
LB-27072
La base de données LB-72072 est identique à la base LB-2880, mais avec l’addition de 24.192 échantillons (mots) du dictionnaire LOD. Les résultats sont affichés ci-après:
| couches | lot | augmentation | meilleur modèle acoustique | WER | CER | LOSS | |
| 1024 | 16 | sans | best_dev-25600 | 0.729 | 0.253 | 94.2 | |
| 2048 | 16 | sans | best_dev-19200 | 0.732 | 0.247 | 97.2 | |
| 2048 | 16 | interne | best_dev-41600 | 0.870 | 0.338 | 92.8 |
Comparaison
Contrairement à mes attentes, l’inclusion de tous les mots du dictionnaire LOD ne produit pas un meilleur modèle STT, au contraire. Les métriques des modèles LB-27072 sont globalement moins performants que celles des modèles entraînés avec la base de données LB-2880. Je vais prochainement explorer si la base de données LB-27072 présente des avantages pour l’entraînement d’un modèle TTS.
Les performances des cinq modèles entraînés avec la base de données LB-2880 ne diffèrent pas sensiblement. Je me propose de retenir le modèle à 1024 couches et entraîné sans augmentation de données comme meilleur modèle acoustique.
Tensorflow Lite
Il est recommandé de convertir le meilleur modèle en format Tensorflow Lite (.tflite) pour pouvoir le déployer sur des systèmes à ressources restreintes comme des mobilophones. Le script pour exporter le modèle est le suivant:
python3 -m coqui_stt_training.train \
--checkpoint_dir /home/mbarnig/STT/losanaju-camaguje/lb-datasets/checkpoints-2880-1024/ \
--export_dir /home/mbarnig/STT/losanaju-camaguje/lb-datasets/exported-model \
--export_tflite trueLe modèle exporté a une taille de 12.2 MB. Je signale qu’il existe un standard ouvert pour les modèles AI, appelé ONNX (Open Neural Network Exchange), qui n’est pas encore supporté par Coqui-STT.
Modèle de langage
Un système de reconnaissance de la parole ne comporte pas seulement un modèle acoustique comme nous l’avons vu jusqu’à présent, mais également un modèle de langage qui permet de corriger et de parfaire les résultats du modèle acoustique. L’outil KenML représente actuellement l’état d’art dans la création d’un modèle de langage. HuggingFace et Coqui-STT supportent tous les deux cet outil, en combinaison avec le modèle acoustique.
Dans le cas du projet Coqui-STT, dont le code est exécuté dans un conteneur Docker, sans intégration de l’outil KenML, la réalisation du modèle de langage luxembourgeois demande quelques bricolages informatiques. J’ai toutefois réussi à créer un modèle de langage à l’aide de la base de données LB-27072. Ce modèle se présente comme suit et comprend un vocabulaire de 25.000 mots uniques.
kenlm-luxembourgish.scorer 2.2 MB
lm.binary 887,6 kB
vocab-25000.txt 271,5 kBComparaison des modèles HuggingFace et Coqui-STT
A la fin de cet exposé il convient de comparer les performances de mon meilleur modèle acoustique Coqui-STT, combiné avec mon modèle de langage KenML, avec celles du modèle pgilles/wavevec2-large-xls-r-LUXEMBOURGISH-with-LM.
A ces fins j’ai sélectionné au hasard cinq échantillons qui ne font pas partie des entraînements effectués sur les deux modèles:
- wavs/Braun_066.wav,233912,hues de do nach wierder et koum en donnerwieder an et huet emol net gereent
- wavs/alles_besser-31.wav,168348,déngschtleeschtungen a wueren ginn automatesch och ëm zwee komma fënnef prozent adaptéiert
- wavs/lb-northwind-0002.wav,82756,an der zäit hunn sech den nordwand an d’sonn gestridden
- wavs/mbarnig-gsm-75.wav,104952,a wou den deemolege president et war e finnlänner
- wavs/dictate_dict9-18.wav,182188,dobäi muss de bierger imperativ op allen niveaue méi am mëttelpunkt stoen
Les résultats sont présentés dans le tableau qui suit:
| transcription source | reconnaissance HuggingFace | WER | reconnaissance Coqui-STT | WER |
| hues de do nach wierder et koum en donnerwieder an et huet emol net gereent | hues de do nach wierder et koum en donnerwieder an etude monet gereent | 0.267 | hues de do nach wierder et koum en donnerwieder an et huet mol net gereent | 0.067 |
| déngschtleeschtungen a wueren ginn automatesch och ëm zwee komma fënnef prozent adaptéiert | déng schlecht jungenawouren ginautomatech or zweker a déiert | 1.0 | angscht leescht engen a wueren ginn automatesch och am zwee komma fanne prozent adapter | 0.500 |
| an der zäit hunn sech den nordwand an d’sonn gestridden | an der zäit hunn sech de nocturnen zon gestridden | 0.4 | an der zeitung sech e nach finanzen lescht rieden | 0.700 |
| a wou den deemolege president et war e finnlänner | wou den deemolege president war e finnlänner | 0.222 | a wou den deemolege president et war finn aner | 0.222 |
| dobäi muss de bierger imperativ op allen niveaue méi am mëttelpunkt stoen | dobäi muss de bierger imperativ op alle nivo méi a mëttepunkt stoen | 0.333 | do bei muss de bierger imperativ op allen niveaue ma am et e punkt stoen | 0.500 |
Conclusions
Il semble que le modèle HuggingFace fait moins d’erreurs, mais je pense qu’il faut faire plus de tests pour évaluer correctement la performance des deux modèles. Les résultats me réconfortent de continuer l’exploration du modèle Coqui-STT avec un apprentissage à partir de zéro. Je me propose de suivre les pistes suivantes:
- étendre ma base de données LB-2880 avec la création d’échantillons supplémentaires à partir d’enregistrements audio de RTL Radio pour parfaire mes modèles Coqui-STT et Coqui-TTS
- porter le modèle Coqui-STT sur iPhone
- examiner la possibilité d’extension de ma base de données STT moyennant des échantillons synthétiques créés à l’aide de modèles TTS luxembourgeois
- explorer l’utilisation de l’augmentation des données et d’échantillons synthétiques sur mon modèle HuggingFace
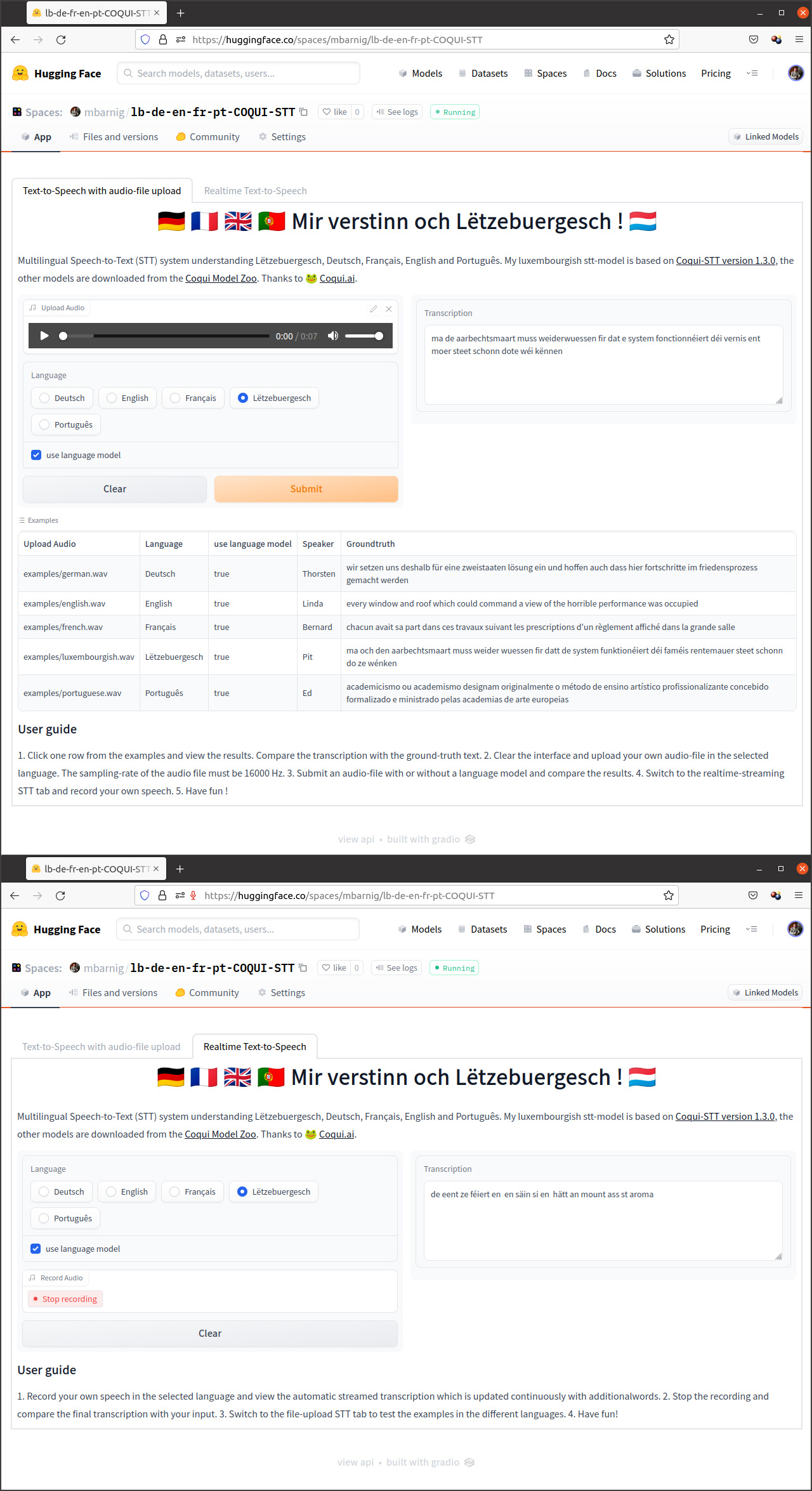
Application interactive de démonstration
J’ai publié le 31 juillet 2022 une application interactive lb-de-en-fr-pt-COQUI-STT de mon modèle sur la plateforme d’intelligence artificielle Huggingface. Veuillez utiliser un navigateur Chrome pour explorer la démo.
Bibliographie
- A Journey to <10% Word Error Rate, Reuben Morais
- Fine-Tune Wav2Vec2 for English ASR with 🤗 Transformers, Patrick von Platen
- A Gentle Introduction to Dropout for Regularizing Deep Neural Networks, Jason Brownlee
- Improving Luxembourgish speech recognition performance, Leminh Nguyen
- A single speaker is almost all you need for automatic speech recognition, Edresson Casanova et al.
- Audio Augmentation for Speech Recognition, Tom Ko et al.